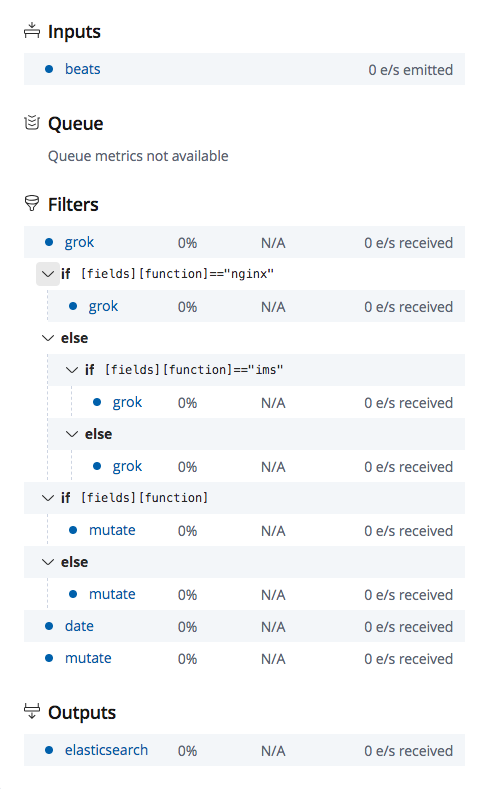
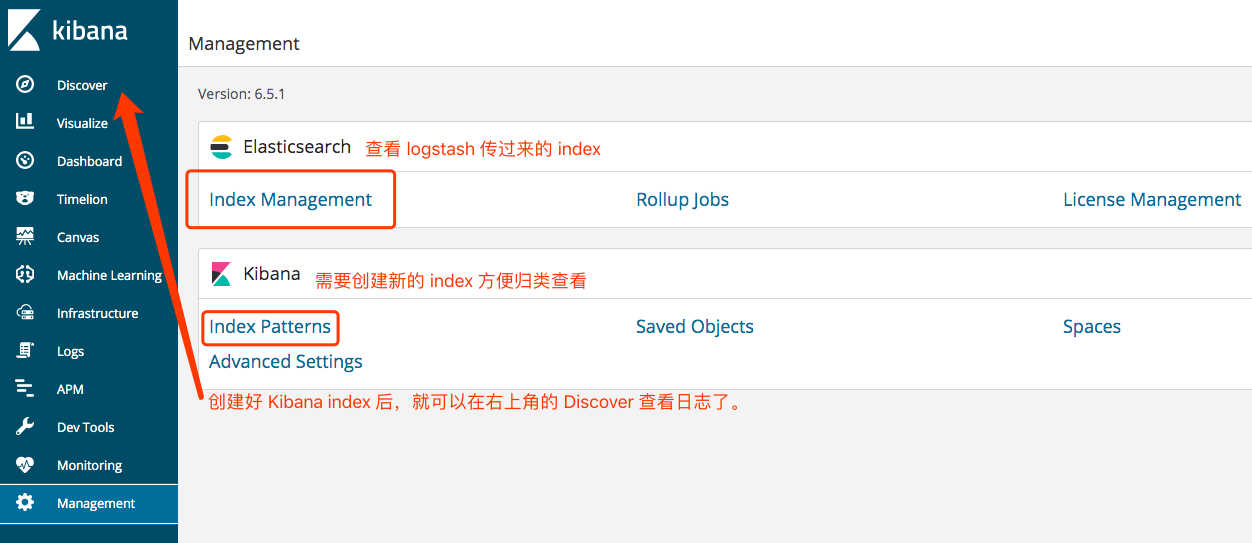
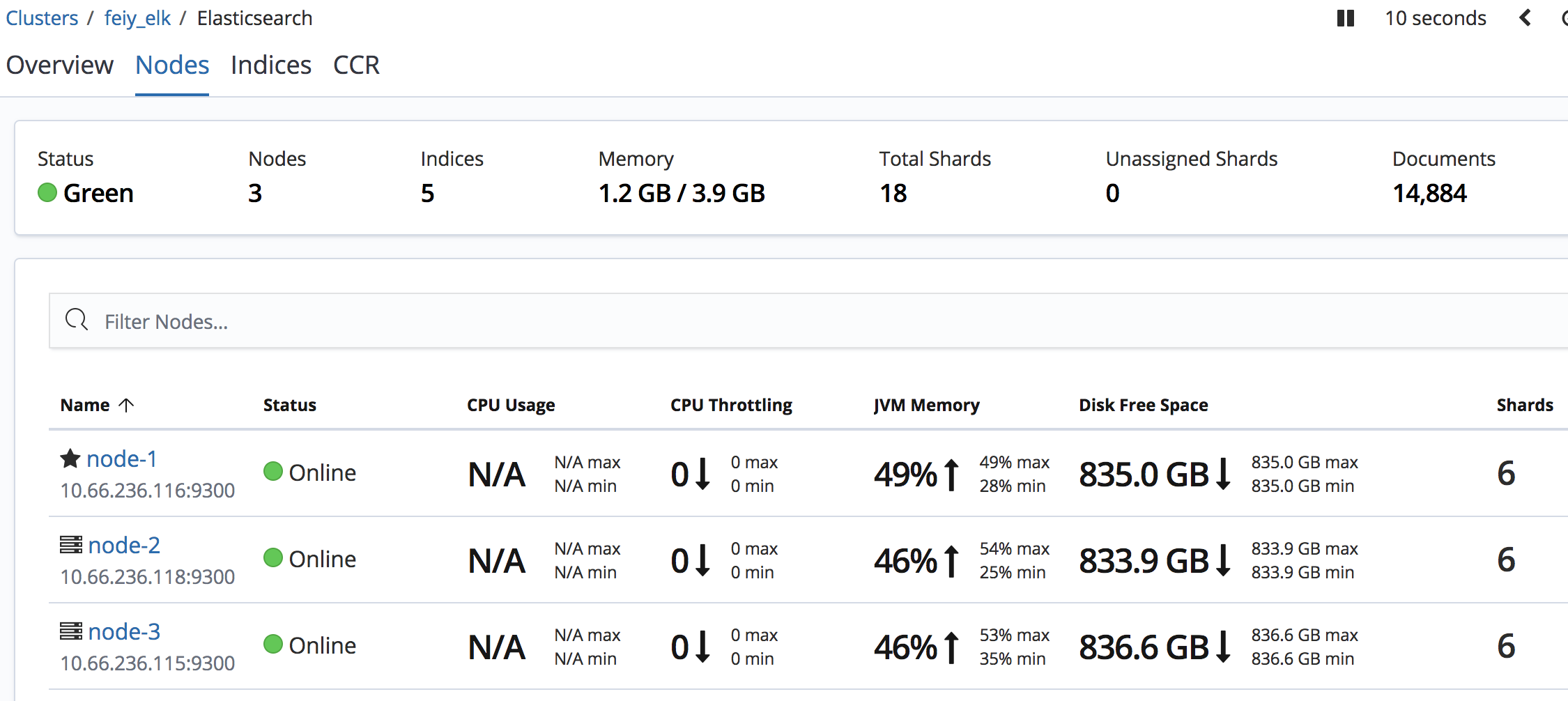
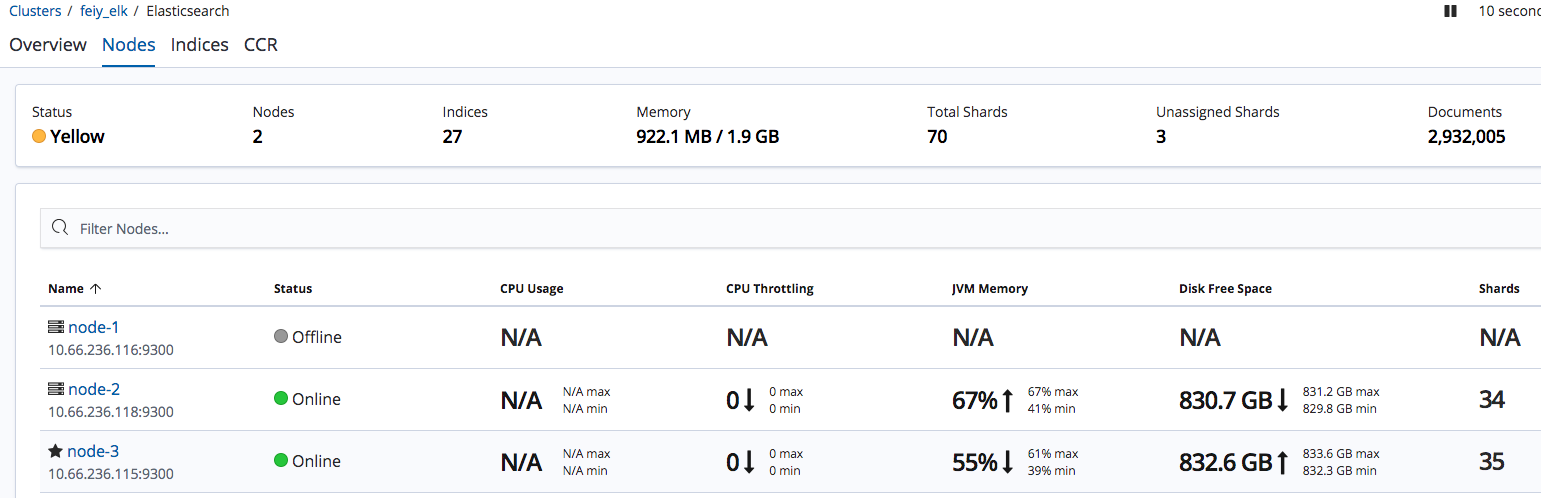
ES_HEAP_SIZE Elasticsearch will assign the entire heap specified in jvm.options via the Xms (minimum heap size) and Xmx (maximum heap size) settings. You should set these two settings to be equal to each other. Set Xmx and Xms to no more than 50% of your physical RAM.the exact threshold varies but is near 32 GB. the exact threshold varies but 26 GB is safe on most systems, but can be as large as 30 GB on some systems. 利弊关系: The more heap available to Elasticsearch, the more memory it can use for its internal caches, but the less memory it leaves available for the operating system to use for the filesystem cache. Also, larger heaps can cause longer garbage collection pauses.
若是采用上述这个三合一的 docker 镜像,官方文档, 对于 ELK 的日志,处理的方式为 Note that ELK’s logs are rotated daily and are deleted after a week, using logrotate. You can change this behaviour by overwriting the elasticsearch, logstash and kibana files in /etc/logrotate.d
1 2
# 每天的 6:25 会对日志进行分割压缩处理,此时对机器的 disk 有大量的 IO 工作,会导致 system load 上升。 25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
这里的解决办法请看下文的自定义部分。
使用Elasticsearch的REST Client的An HTTP line is larger than 4096 bytes {“type”:”too_long_frame_exception”,”reason”:”An HTTP line is larger than 4096 bytes.”},默认情况下ES对请求参数设置为4K,如果遇到请求参数长度限制可以在elasticsearch.yml中修改如下参数: 请参考官方文档
filebeat.inputs: -type:log enabled:true paths:# 需要收集的日志 -/var/log/app/**## ** need high versiob filebeat can support recursive exclude_files: ['^/var/log/ocha/no_need_foler/']
fields:#需要添加的字段 host:"{{inventory_hostname}}" function:"xxx" multiline:# 多行匹配 match:after negate:true# pay attention the format pattern:'^\[[0-9]{4}-[0-9]{2}-[0-9]{2}'#\[ ignore_older:24h clean_inactive:72h
# vi /usr/share/logstash/config/logstash.yml # 需要把 url 改为 elasticsearch master 节点的 IP http.host:"0.0.0.0" xpack.monitoring.elasticsearch.url:http://elasticsearch_master_IP:9200 node.name:"feiy" pipeline.workers:24# same with cores
Quick intro to the UI The Console UI is split into two panes: an editor pane (left) and a response pane (right). Use the editor to type requests and submit them to Elasticsearch. The results will be displayed in the response pane on the right side.
Console understands requests in a compact format, similar to cURL:
1 2 3 4 5 6 7 8
# index a doc PUT index/type/1 { "body": "here" }
# and get it ... GET index/type/1
While typing a request, Console will make suggestions which you can then accept by hitting Enter/Tab. These suggestions are made based on the request structure as well as your indices and types.
A few quick tips, while I have your attention
Submit requests to ES using the green triangle button.
Use the wrench menu for other useful things.
You can paste requests in cURL format and they will be translated to the Console syntax.
You can resize the editor and output panes by dragging the separator between them.
Study the keyboard shortcuts under the Help button. Good stuff in there!
# Delete all indices in your Elastic Search cluster for i in `curl 'localhost:9200/_cat/indices?v' | tail -n +2 | awk '{print $3}'`; do curl -XDELETE "http://127.0.0.1:9200/$i"; done
# vim delete_elk.sh
#!/bin/bash for i in `curl 'localhost:9200/_cat/indices?v' | tail -n +2 | awk '{print $3}'`; do curl -XDELETE "http://127.0.0.1:9200/$i"; done sleep 5s systemctl restart elasticsearch
“message”:”Alias [.kibana] has more than one indices associated with it [[.kibana_1, .kibana_2]] 这是因为 kibana 连接了一台机器,如果我们把这台 host 和 kibana 删除,但 kibana 的数据还会在另外两台 host上。当重新创建 host 加入时,会自动同步 .kibana,kibana 就会报错
[2019-11-21T19:18:21,800][FATAL][logstash.runner] An unexpected error occurred! {:error=><ArgumentError: Path "/var/lib/logstash/dead_letter_queue" must be a writable directory. It is not writable.
once disk usage more than 95%, elasticseach will stop store new data to index, and will add lock for these index. Even you release the disk, the lock is still enable. elk cannot store new data to read-only index. you will see the error log in logstash
The index option controls whether field values are indexed. It accepts true or false and defaults to true. Fields that are not indexed are not queryable.
[2020-02-03T00:00:12,211][DEBUG][o.e.a.s.TransportSearchAction] [localhost.localdomain] All shards failed for phase: [query] org.elasticsearch.ElasticsearchException$1: Fielddata is disabled on text fields by default. Set fielddata=true on [type] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead. at org.elasticsearch.ElasticsearchException.guessRootCauses(ElasticsearchException.java:639) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.search.AbstractSearchAsyncAction.executeNextPhase(AbstractSearchAsyncAction.java:137) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.search.AbstractSearchAsyncAction.onPhaseDone(AbstractSearchAsyncAction.java:273) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.search.InitialSearchPhase.onShardFailure(InitialSearchPhase.java:105) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.search.InitialSearchPhase.access$200(InitialSearchPhase.java:50) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.search.InitialSearchPhase$2.onFailure(InitialSearchPhase.java:273) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.search.SearchExecutionStatsCollector.onFailure(SearchExecutionStatsCollector.java:73) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.ActionListenerResponseHandler.handleException(ActionListenerResponseHandler.java:59) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.search.SearchTransportService$ConnectionCountingHandler.handleException(SearchTransportService.java:424) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.transport.TransportService$ContextRestoreResponseHandler.handleException(TransportService.java:1120) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.transport.TransportService$DirectResponseChannel.processException(TransportService.java:1229) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.transport.TransportService$DirectResponseChannel.sendResponse(TransportService.java:1203) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.transport.TaskTransportChannel.sendResponse(TaskTransportChannel.java:60) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.support.ChannelActionListener.onFailure(ChannelActionListener.java:56) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.ActionListener$1.onFailure(ActionListener.java:70) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.ActionListener$1.onResponse(ActionListener.java:64) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.SearchService.lambda$rewriteShardRequest$7(SearchService.java:1043) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.ActionRunnable$1.doRun(ActionRunnable.java:45) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.common.util.concurrent.TimedRunnable.doRun(TimedRunnable.java:44) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:773) [elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37) [elasticsearch-7.4.2.jar:7.4.2] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) [?:?] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) [?:?] at java.lang.Thread.run(Thread.java:830) [?:?] Caused by: java.lang.IllegalArgumentException: Fielddata is disabled on text fields by default. Set fielddata=true on [type] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead. at org.elasticsearch.index.mapper.TextFieldMapper$TextFieldType.fielddataBuilder(TextFieldMapper.java:759) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.index.fielddata.IndexFieldDataService.getForField(IndexFieldDataService.java:116) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.index.query.QueryShardContext.getForField(QueryShardContext.java:191) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.aggregations.support.ValuesSourceConfig.resolve(ValuesSourceConfig.java:112) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.aggregations.support.ValuesSourceAggregationBuilder.resolveConfig(ValuesSourceAggregationBuilder.java:350) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.aggregations.support.ValuesSourceAggregationBuilder.doBuild(ValuesSourceAggregationBuilder.java:322) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.aggregations.support.ValuesSourceAggregationBuilder.doBuild(ValuesSourceAggregationBuilder.java:39) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.aggregations.AbstractAggregationBuilder.build(AbstractAggregationBuilder.java:139) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.aggregations.AggregatorFactories$Builder.build(AggregatorFactories.java:332) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.SearchService.parseSource(SearchService.java:784) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.SearchService.createContext(SearchService.java:586) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.SearchService.createAndPutContext(SearchService.java:545) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.SearchService.executeQueryPhase(SearchService.java:348) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.search.SearchService.lambda$executeQueryPhase$1(SearchService.java:340) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.ActionListener.lambda$map$2(ActionListener.java:145) ~[elasticsearch-7.4.2.jar:7.4.2] at org.elasticsearch.action.ActionListener$1.onResponse(ActionListener.java:62) ~[elasticsearch-7.4.2.jar:7.4.2] ... 9 more
es cluster
If we use domain for es cluster node load balance, we must specify the port, because kibana will use default port is 9200. But nginx load balance port is 80 or 443. If we use wrong port, the error is kibana Request Timeout after 3000ms
自定义部分
自动删除 index
因为我是按周数来 %{+xxxx.ww} 存 index,由于我们的存储机器硬盘有限,最多能存放两个周的日志,所以需要删除两周之前的 index