以此文来记录一下,我自己觉得鲜为人知的知识点。 我个人比较喜欢的网站 Learn Python Programming
更新历史
2021 年 06 月 17 日 - 更新数据结构与算法全景, 全剧终
2020 年 10 月 09 日 - 更新单元测试,调试和性能分析
2020 年 09 月 29 日 - 规范代码风格
2020 年 09 月 26 日 - Asyncio 协程,垃圾回收, GIL, 多进程与多线程选择
2020 年 09 月 25 日 - 生成器的特性,next() 函数运行的时候,保存了当前的指针
2020 年 09 月 24 日 - 进阶篇 list 拼接返回的是一个新的对象
2020 年 09 月 23 日 - 增加基础篇
2020 年 09 月 22 日 - 初稿
知识图谱
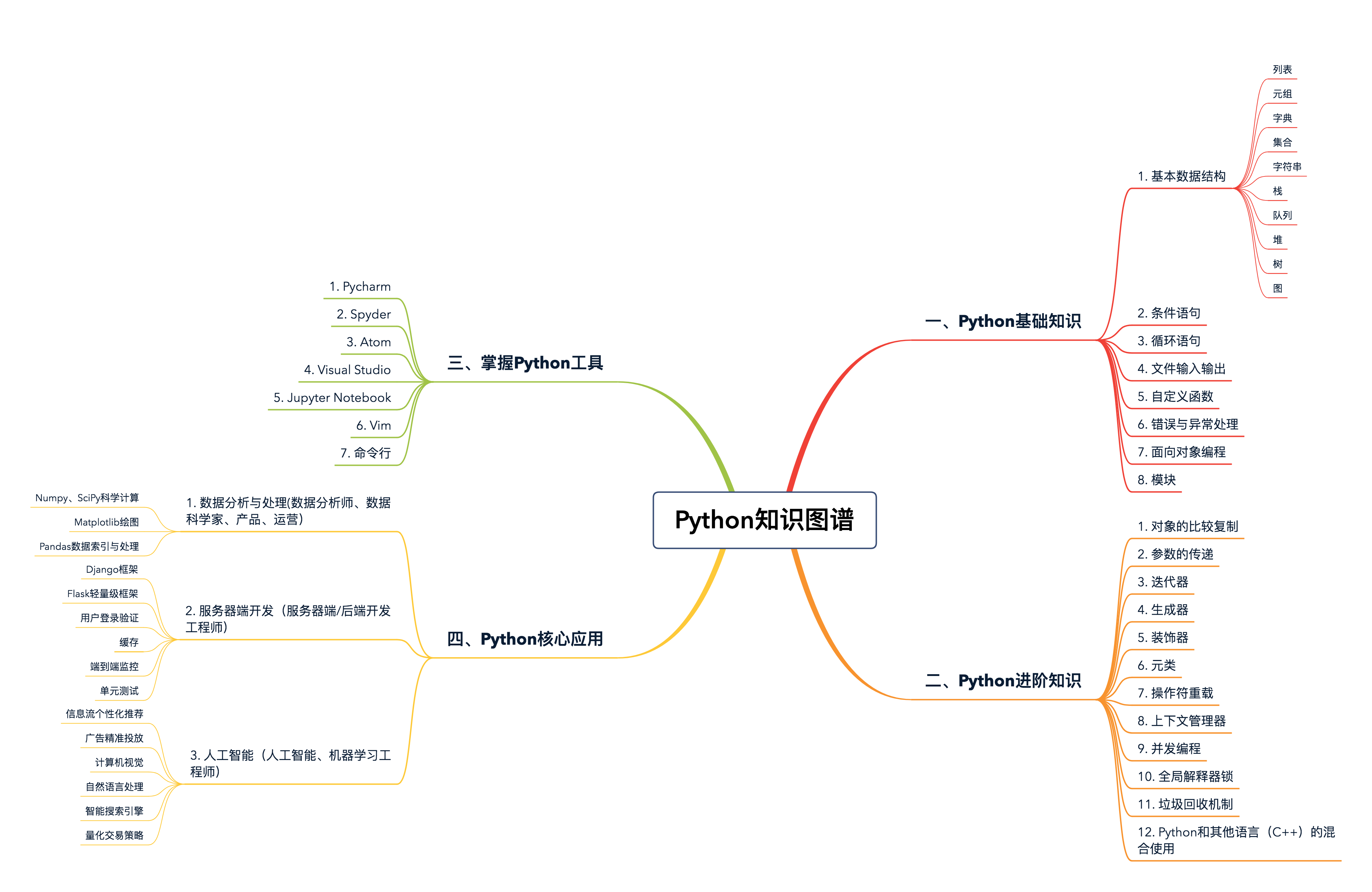
基础篇
不可变类型
- int
- float
- decimal
- complex
- bool
- string
- tuple
- range
- frozenset
- bytes
可变类型
- list
- dict
- set
- bytearray
- user-defined classes (unless specifically made immutable)
列表和元组
列表是动态的,长度大小不固定,可以随意地增加、删减或者改变元素(mutable)。
而元组是静态的,长度大小固定,无法增加删减或者改变(immutable)。
列表和元组常用的内置函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21l = [3, 2, 3, 7, 8, 1]
l.count(3)
2
l.index(7)
3
l.reverse()
l
[1, 8, 7, 3, 2, 3]
l.sort()
l
[1, 2, 3, 3, 7, 8]
tup = (3, 2, 3, 7, 8, 1)
tup.count(3)
2
tup.index(7)
3
list(reversed(tup))
[1, 8, 7, 3, 2, 3]
sorted(tup)
[1, 2, 3, 3, 7, 8]列表和元组存储方式的差异:
1
2
3
4
5
6l = [1, 2, 3]
l.__sizeof__()
64
tup = (1, 2, 3)
tup.__sizeof__()
48由于列表是动态的,所以它需要存储指针,来指向对应的元素(上述例子中,对于 int 型,8 字节)。另外,由于列表可变,所以需要额外存储已经分配的长度大小(8 字节),这样才可以实时追踪列表空间的使用情况,当空间不足时,及时分配额外空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18l = []
l.__sizeof__() // 空列表的存储空间为 40 字节
40
l.append(1)
l.__sizeof__()
72 // 加入了元素 1 之后,列表为其分配了可以存储 4 个元素的空间 (72 - 40)/8 = 4
l.append(2)
l.__sizeof__()
72 // 由于之前分配了空间,所以加入元素 2,列表空间不变
l.append(3)
l.__sizeof__()
72 // 同上
l.append(4)
l.__sizeof__()
72 // 同上
l.append(5)
l.__sizeof__()
104 // 加入元素 5 之后,列表的空间不足,所以又额外分配了可以存储 4 个元素的空间创建一个空的列表,我们可以用下面的 A、B 两种方式,请问它们在效率上有什么区别吗?我们应该优先考虑使用哪种呢?
1
2
3
4
5
6# 创建空列表
# option A
empty_list = list()
# option B
empty_list = []用list()方法构造一个空列表使用的是class list([iterable])的类型构造器,参数可以是一个iterable,如果没有给出参数,构造器将创建一个空列表[ ],相比较而言多了一步class调用和参数判断,所以用 [ ] 直接构造一个空列表的方法速度更快
关于多变量赋值:https://blog.csdn.net/qq_35398033/article/details/108449977
1 | class Solution: |
三个变量同时赋值,先把右边的 3 个变量打包为元组, 然后再拆包一一对应的赋值给左边。
字典、集合
那究竟什么是字典,什么是集合呢?字典是一系列由键(key)和值(value)配对组成的元素的集合,在 Python3.7+,字典被确定为有序(注意:在 3.6 中,字典有序是一个 implementation detail,在 3.7 才正式成为语言特性,因此 3.6 中无法 100% 确保其有序性),而 3.6 之前是无序的,其长度大小可变,元素可以任意地删减和改变。
字典访问可以直接索引键,如果不存在,就会抛出异常:KeyError 也可以使用 get(key, default) 函数来进行索引。如果键不存在,调用 get() 函数可以返回一个默认值。
集合并不支持索引操作,因为集合本质上是一个哈希表,和列表不一样。
想要判断一个元素在不在字典或集合内,我们可以用 value in dict/set 来判断。
1
2
3
4
5
6
7
8
9
10
11s = {1, 2, 3}
1 in s
True
10 in s
False
d = {'name': 'jason', 'age': 20}
'name' in d
True
'location' in d
False集合的 pop() 操作是删除集合中最后一个元素,可是集合本身是无序的,你无法知道会删除哪个元素,因此这个操作得谨慎使用。
对于字典,我们通常会根据键或值,进行升序或降序排序:
1
2
3
4
5
6
7d = {'b': 1, 'a': 2, 'c': 10}
d_sorted_by_key = sorted(d.items(), key=lambda x: x[0]) # 根据字典键的升序排序
d_sorted_by_value = sorted(d.items(), key=lambda x: x[1]) # 根据字典值的升序排序
d_sorted_by_key
[('a', 2), ('b', 1), ('c', 10)]
d_sorted_by_value
[('b', 1), ('a', 2), ('c', 10)]字典和集合的工作原理: 对于字典而言,这张表存储了哈希值(hash)、键和值这 3 个元素。而对集合来说,区别就是哈希表内没有键和值的配对,只有单一的元素了。
老版本 Python 的哈希表结构如下所示:
1
2
3
4
5
6
7
8
9
10
11--+-------------------------------+
| 哈希值 (hash) 键 (key) 值 (value)
--+-------------------------------+
0 | hash0 key0 value0
--+-------------------------------+
1 | hash1 key1 value1
--+-------------------------------+
2 | hash2 key2 value2
--+-------------------------------+
. | ...
__+_______________________________+不难想象,随着哈希表的扩张,它会变得越来越稀疏。举个例子,比如我有这样一个字典:
1
{'name': 'mike', 'dob': '1999-01-01', 'gender': 'male'}
那么它会存储为类似下面的形式:
1
2
3
4
5
6
7
8
9entries = [
['--', '--', '--']
[-230273521, 'dob', '1999-01-01'],
['--', '--', '--'],
['--', '--', '--'],
[1231236123, 'name', 'mike'],
['--', '--', '--'],
[9371539127, 'gender', 'male']
]这样的设计结构显然非常浪费存储空间。为了提高存储空间的利用率,现在的哈希表除了字典本身的结构,会把索引和哈希值、键、值单独分开,也就是下面这样新的结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Indices
----------------------------------------------------
None | index | None | None | index | None | index ...
----------------------------------------------------
Entries
--------------------
hash0 key0 value0
---------------------
hash1 key1 value1
---------------------
hash2 key2 value2
---------------------
...
---------------------删除操作 对于删除操作,Python 会暂时对这个位置的元素,赋于一个特殊的值,等到重新调整哈希表的大小时,再将其删除。不难理解,哈希冲突的发生,往往会降低字典和集合操作的速度。因此,为了保证其高效性,字典和集合内的哈希表,通常会保证其至少留有 1/3 的剩余空间。随着元素的不停插入,当剩余空间小于 1/3 时,Python 会重新获取更大的内存空间,扩充哈希表。不过,这种情况下,表内所有的元素位置都会被重新排放。虽然哈希冲突和哈希表大小的调整,都会导致速度减缓,但是这种情况发生的次数极少。所以,平均情况下,这仍能保证插入、查找和删除的时间复杂度为 O(1)。
下面初始化字典的方式,哪一种更高效?
1
2
3
4
5# Option A
d = {'name': 'jason', 'age': 20, 'gender': 'male'}
# Option B
d = dict({'name': 'jason', 'age': 20, 'gender': 'male'})第一种方法更快,原因感觉上是和之前一样,就是不需要去调用相关的函数,而且像老师说的那样 {} 应该是关键字,内部会去直接调用底层C写好的代码
字符串
什么是字符串呢?字符串是由独立字符组成的一个序列,通常包含在单引号(’’)双引号(””)或者三引号之中(’’’ ‘’’或””” “””,两者一样
Python 同时支持这三种表达方式,很重要的一个原因就是,这样方便你在字符串中,内嵌带引号的字符串。比如:
1
"I'm a student"
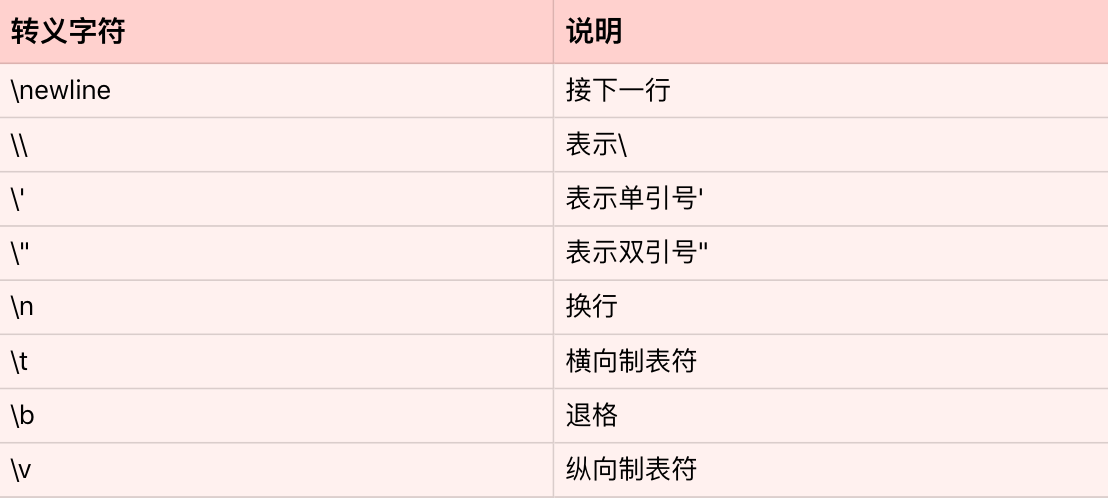
特别要注意,Python 的字符串是不可变的(immutable)。因此,用下面的操作,来改变一个字符串内部的字符是错误的,不允许的。
1
2
3
4
5s = 'hello'
s[0] = 'H'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignmentPython 中字符串的改变,通常只能通过创建新的字符串来完成。比如上述例子中,想把’hello’的第一个字符’h’,改为大写的’H’,我们可以采用下面的做法:
1
2s = 'H' + s[1:]
s = s.replace('h', 'H')使用加法操作符’+=’的字符串拼接方法。因为它是一个例外,打破了字符串不可变的特性。从 Python2.5 开始,每次处理字符串的拼接操作时(str1 += str2),Python 首先会检测 str1 还有没有其他的引用。如果没有的话,就会尝试原地扩充字符串 buffer 的大小,而不是重新分配一块内存来创建新的字符串并拷贝。
字符串的格式化
1
print('no data available for person with id: {}, name: {}'.format(id, name))
输入与输出
- input() 函数暂停程序运行,同时等待键盘输入;直到回车被按下,函数的参数即为提示语,输入的类型永远是字符串型(str)。
- json.dumps() 这个函数,接受 Python 的基本数据类型,然后将其序列化为 string;
- json.loads() 这个函数,接受一个合法字符串,然后将其反序列化为 Python 的基本数据类型。
条件与循环
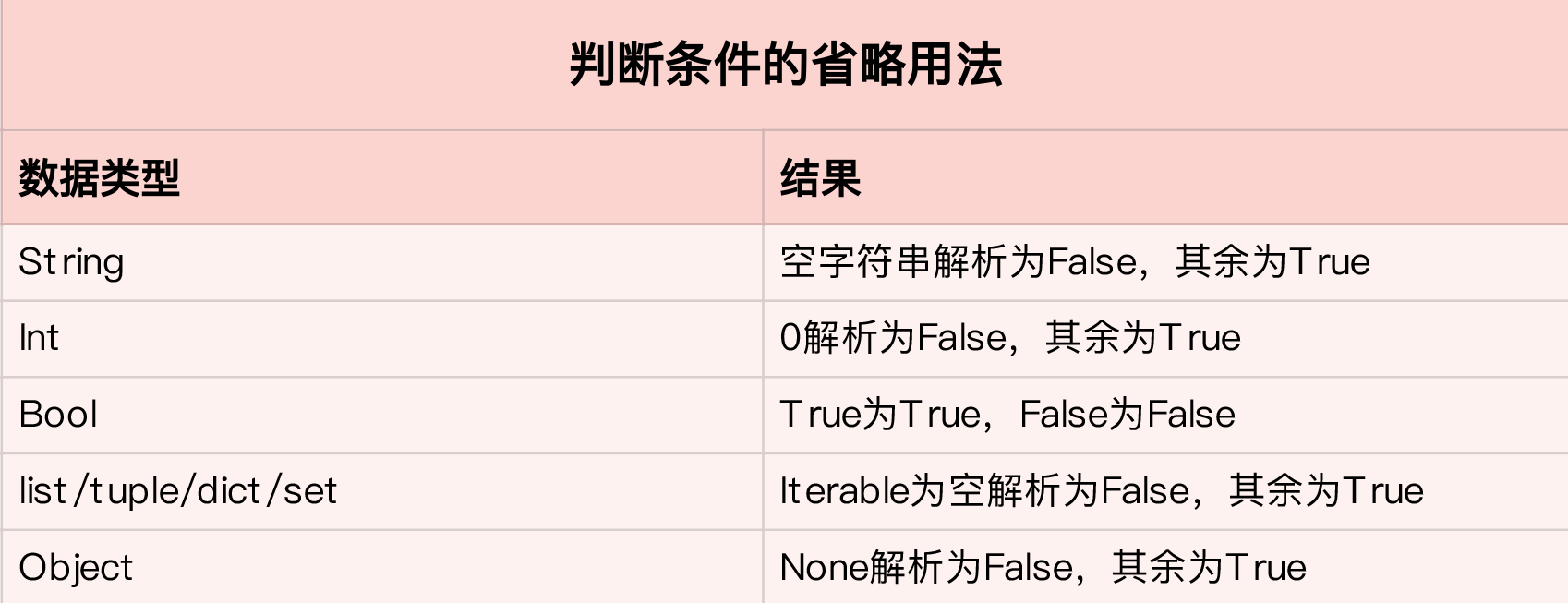
在实际写代码时,我们鼓励,除了 boolean 类型的数据,条件判断最好是显性的。比如,在判断一个整型数是否为 0 时,我们最好写出判断的条件:
1
2if i != 0:
...而不是只写出变量名:
1
2if i:
...刷题时,反转链表那一题:只写变量名字, 判断链表时, call bool() 耗费的时间太多了
https://stackoverflow.com/questions/7816363/if-a-vs-if-a-is-not-none当我们同时需要索引和元素时,还有一种更简洁的方式,那就是通过 Python 内置的函数 enumerate()。用它来遍历集合,不仅返回每个元素,并且还返回其对应的索引
1
2
3
4
5
6
7
8
9
10l = [1, 2, 3, 4, 5, 6, 7]
for index, item in enumerate(l):
if index < 5:
print(item)
1
2
3
4
5在循环语句中,我们还常常搭配 continue 和 break 一起使用。所谓 continue,就是让程序跳过当前这层循环,继续执行下面的循环;而 break 则是指完全跳出所在的整个循环体。在循环中适当加入 continue 和 break,往往能使程序更加简洁、易读。
for 循环和 while 循环可以互相转换。通常来说,如果你只是遍历一个已知的集合,找出满足条件的元素,并进行相应的操作,那么使用 for 循环更加简洁。但如果你需要在满足某个条件前,不停地重复某些操作,并且没有特定的集合需要去遍历,那么一般则会使用 while 循环。
for 循环和 while 循环的效率问题。比如下面的 while 循环:
1
2
3i = 0
while i < 1000000:
i += 1和等价的 for 循环:
1
2for i in range(0, 1000000):
passrange() 函数是直接由 C 语言写的,调用它速度非常快。而 while 循环中的“i += 1”这个操作,得通过 Python 的解释器间接调用底层的 C 语言;并且这个简单的操作,又涉及到了对象的创建和删除(因为 i 是整型,是 immutable,i += 1 相当于 i = new int(i + 1))。所以,显然,for 循环的效率更胜一筹。
expression1 if condition else expression2 for item in iterable
1
2
3
4
5for item in iterable:
if condition:
expression1
else:
expression2而如果没有 else 语句,则需要写成:expression for item in iterable if condition
[(xx, yy) for xx in x for yy in y if xx != yy]
1
2
3
4
5l = []
for xx in x:
for yy in y:
if xx != yy:
l.append((xx, yy))[dict(zip(attributes, value)) for value in values]
1
2
3
4
5
6
7
8
9
10attributes = ['name', 'dob', 'gender']
values = [['jason', '2000-01-01', 'male'],
['mike', '1999-01-01', 'male'],
['nancy', '2001-02-01', 'female']
]
# expected outout:
[{'name': 'jason', 'dob': '2000-01-01', 'gender': 'male'},
{'name': 'mike', 'dob': '1999-01-01', 'gender': 'male'},
{'name': 'nancy', 'dob': '2001-02-01', 'gender': 'female'}]
异常处理
- 程序中的错误至少包括两种,一种是语法错误,另一种则是异常。
- 很多时候,我们很难保证程序覆盖所有的异常类型,所以,更通常的做法,是在最后一个 except block,声明其处理的异常类型是 Exception。Exception 是其他所有非系统异常的基类,能够匹配任意非系统异常。
1
2
3
4
5
6
7
8
9
10
11
12
13try:
s = input('please enter two numbers separated by comma: ')
num1 = int(s.split(',')[0].strip())
num2 = int(s.split(',')[1].strip())
...
except ValueError as err:
print('Value Error: {}'.format(err))
except IndexError as err:
print('Index Error: {}'.format(err))
except Exception as err:
print('Other error: {}'.format(err))
print('continue') - 当程序中存在多个 except block 时,最多只有一个 except block 会被执行。换句话说,如果多个 except 声明的异常类型都与实际相匹配,那么只有最前面的 except block 会被执行,其他则被忽略。
- 异常处理中,还有一个很常见的用法是 finally,经常和 try、except 放在一起来用。无论发生什么情况,finally block 中的语句都会被执行,哪怕前面的 try 和 excep block 中使用了 return 语句。
- 用户自定义异常
- When an exception has been assigned using as target, it is cleared at the end of the except clause. 这句话意思是,如果你在异常处理的 except block 中,把异常赋予了一个变量,那么这个变量会在 except block 执行结束时被删除
自定义函数
和其他需要编译的语言(比如 C 语言)不一样的是,def 是可执行语句,这意味着函数直到被调用前,都是不存在的。当程序调用函数时,def 语句才会创建一个新的函数对象,并赋予其名字。
主程序调用函数时,必须保证这个函数此前已经定义过,不然就会报错
如果我们在函数内部调用其他函数,函数间哪个声明在前、哪个在后就无所谓,因为 def 是可执行语句,函数在调用之前都不存在,我们只需保证调用时,所需的函数都已经声明定义
Python 不用考虑输入的数据类型,而是将其交给具体的代码去判断执行,同样的一个函数(比如这边的相加函数 my_sum()),可以同时应用在整型、列表、字符串等等的操作中。在编程语言中,我们把这种行为称为多态。
所谓的函数嵌套,就是指函数里面又有函数。第一,函数的嵌套能够保证内部函数的隐私。第二,合理的使用函数嵌套,能够提高程序的运行效率。
如果变量是在函数内部定义的,就称为局部变量,只在函数内部有效。一旦函数执行完毕,局部变量就会被回收,无法访问
不能在函数内部随意改变全局变量的值
1
2
3
4
5
6
7
8MIN_VALUE = 1
MAX_VALUE = 10
def validation_check(value):
MIN_VALUE += 1
validation_check(5)
UnboundLocalError: local variable 'MIN_VALUE' referenced before assignment如果我们一定要在函数内部改变全局变量的值,就必须加上 global 这个声明。这里的 global 关键字,并不表示重新创建了一个全局变量 MIN_VALUE,而是告诉 Python 解释器,函数内部的变量 MIN_VALUE,就是之前定义的全局变量,并不是新的全局变量,也不是局部变量。这样,程序就可以在函数内部访问全局变量,并修改它的值了。另外,如果遇到函数内部局部变量和全局变量同名的情况,那么在函数内部,局部变量会覆盖全局变量
对于嵌套函数来说,内部函数可以访问外部函数定义的变量,但是无法修改,若要修改,必须加上 nonlocal 这个关键字:
1
2
3
4
5
6
7
8
9
10
11
12def outer():
x = "local"
def inner():
nonlocal x # nonlocal 关键字表示这里的 x 就是外部函数 outer 定义的变量 x
x = 'nonlocal'
print("inner:", x)
inner()
print("outer:", x)
outer()
# 输出
inner: nonlocal
outer: nonlocal如果不加上 nonlocal 这个关键字,而内部函数的变量又和外部函数变量同名,那么同样的,内部函数变量会覆盖外部函数的变量。
1
2
3
4
5
6
7
8
9
10
11def outer():
x = "local"
def inner():
x = 'nonlocal' # 这里的 x 是 inner 这个函数的局部变量
print("inner:", x)
inner()
print("outer:", x)
outer()
# 输出
inner: nonlocal
outer: local闭包(closure)返回的是一个函数
匿名函数
lambda argument1, argument2,… argumentN : expression
匿名函数 lambda 和常规函数一样,返回的都是一个函数对象(function object)
lambda 是一个表达式(expression),并不是一个语句(statement)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# Program to show the use of lambda functions
double = lambda x: x * 2
print(double(5)) # 10
# is nearly the same as:
def double(x):
return x * 2
# Example use with filter()
# Program to filter out only the even items from a list
my_list = [1, 5, 4, 6, 8, 11, 3, 12]
new_list = list(filter(lambda x: (x%2 == 0) , my_list))
print(new_list)
[4, 6, 8, 12]
# Example use with map()
# Program to double each item in a list using map()
my_list = [1, 5, 4, 6, 8, 11, 3, 12]
new_list = list(map(lambda x: x * 2 , my_list))
print(new_list)
[2, 10, 8, 12, 16, 22, 6, 24]所谓的表达式,就是用一系列“公式”去表达一个东西,比如x + 2、 x**2等等;
所谓的语句,则一定是完成了某些功能,比如赋值语句x = 1完成了赋值,print 语句print(x)完成了打印,条件语句 if x < 0:完成了选择功能等等。
所谓函数式编程,是指代码中每一块都是不可变的(immutable),都由纯函数(pure function)的形式组成。这里的纯函数,是指函数本身相互独立、互不影响,对于相同的输入,总会有相同的输出,没有任何副作用。
1
2
3
4def multiply_2(l):
for index in range(0, len(l)):
l[index] *= 2
return l这段代码就不是一个纯函数的形式,因为列表中元素的值被改变了,如果我多次调用 multiply_2() 这个函数,那么每次得到的结果都不一样。要想让它成为一个纯函数的形式,就得写成下面这种形式,重新创建一个新的列表并返回。
1
2
3
4
5def multiply_2_pure(l):
new_list = []
for item in l:
new_list.append(item * 2)
return new_list函数式编程的优点,主要在于其纯函数和不可变的特性使程序更加健壮,易于调试(debug)和测试;缺点主要在于限制多,难写。
map(function, iterable)
1
2
3
4
5
6
7
8python3 -mtimeit -s'xs=range(1000000)' 'map(lambda x: x*2, xs)'
2000000 loops, best of 5: 171 nsec per loop
python3 -mtimeit -s'xs=range(1000000)' '[x * 2 for x in xs]'
5 loops, best of 5: 62.9 msec per loop
python3 -mtimeit -s'xs=range(1000000)' 'l = []' 'for i in xs: l.append(i * 2)'
5 loops, best of 5: 92.7 msec per loopmap() 是最快的。因为 map() 函数直接由 C 语言写的,运行时不需要通过 Python 解释器间接调用,并且内部做了诸多优化,所以运行速度最快。
对一个字典,根据值进行由高到底的排序
1
2
3
4
5
6
7
8
9
10
11d = {'mike': 10, 'lucy': 2, 'ben': 30}
sorted(d.items(), key=lambda x: x[1], reverse=True)
# 解释一下 Python Dictionary items()
# returns a view object that displays a list of a given dictionary's (key, value) tuple pair.
# random sales dictionary
sales = { 'apple': 2, 'orange': 3, 'grapes': 4 }
print(sales.items())
dict_items([('apple', 2), ('orange', 3), ('grapes', 4)])
面向对象
- 面向对象编程四要素是:类,属性,函数,对象,
- OOP (object oriented programming)
- 如果一个属性以 __ (注意,此处有两个 _) 开头,我们就默认这个属性是私有属性。私有属性,是指不希望在类的函数之外的地方被访问和修改的属性
- 类函数、成员函数和静态函数三个概念。它们其实很好理解,前两者产生的影响是动态的,能够访问或者修改对象的属性;而静态函数则与类没有什么关联,最明显的特征便是,静态函数的第一个参数没有任何特殊性。
- 首先需要注意的是构造函数。每个类都有构造函数,继承类在生成对象的时候,是不会自动调用父类的构造函数的,因此你必须在 init() 函数中显式调用父类的构造函数。它们的执行顺序是 子类的构造函数 -> 父类的构造函数。
- 抽象类是一种特殊的类,它生下来就是作为父类存在的,一旦对象化就会报错。同样,抽象函数定义在抽象类之中,子类必须重写该函数才能使用。相应的抽象函数,则是使用装饰器 @abstractmethod 来表示。
- super(Parents_Name, self).init()直接初始化该类的第一个父类,不过使用这种方法时,要求继承链的最顶层父类必须要继承 object;
- 对于多重继承,如果有多个构造函数需要调用, 我们就必须用传统的方法 LRUCache.init(self) 。
Python 模块化
- import 同一个模块只会被执行一次,这样就可以防止重复导入模块出现问题。当然,良好的编程习惯应该杜绝代码多次导入的情况。在 Facebook 的编程规范中,除了一些极其特殊的情况,import 必须位于程序的最前端。
- 你可能在许多教程中看到过这样的要求:我们还需要在模块所在的文件夹新建一个 init.py,内容可以为空,也可以用来表述包对外暴露的模块接口。不过,事实上,这是 Python 2 的规范。在 Python 3 规范中,init.py 并不是必须的,很多教程里没提过这一点,或者没讲明白,我希望你还是能注意到这个地方。
- 一个 Python 文件在运行的时候,都会有一个运行时位置,最开始时即为这个文件所在的文件夹。
- 以项目的根目录作为最基本的目录,所有的模块调用,都要通过根目录一层层向下索引的方式来 import。
- Python 解释器在遇到 import 的时候,它会在一个特定的列表中寻找模块。这个特定的列表,可以用下面的方式拿到:修改 PYTHONHOME。Python 的 Virtual Environment(虚拟运行环境)。Python 可以通过 Virtualenv 工具,非常方便地创建一个全新的 Python 运行环境。
1
2
3
4
5
6
7import sys
print(sys.path)
########## 输出 ##########
['', '/usr/lib/python36.zip', '/usr/lib/python3.6', '/usr/lib/python3.6/lib-dynload', '/usr/local/lib/python3.6/dist-packages', '/usr/lib/python3/dist-packages'] - 神奇的 if name == ‘main‘ Python 是脚本语言,和 C++、Java 最大的不同在于,不需要显式提供 main() 函数入口。既然 Python 可以直接写代码,if name == ‘main‘ 这样的写法,除了能让 Python 代码更好看(更像 C++ )外,还有什么好处吗?import 在导入文件的时候,会自动把所有暴露在外面的代码全都执行一遍。因此,如果你要把一个东西封装成模块,又想让它可以执行的话,你必须将要执行的代码放在 if name == ‘main‘下面。
列表和元组的内部实现
- Python 3.7 的 list 源码。
listobject.h:https://github.com/python/cpython/blob/949fe976d5c62ae63ed505ecf729f815d0baccfc/Include/listobject.h#L23
listobject.c: https://github.com/python/cpython/blob/3d75bd15ac82575967db367c517d7e6e703a6de3/Objects/listobject.c#L33
list 本质上是一个 over-allocate 的 array。allocated >= len(list) = ob_size。 - 我们再来分析元组。下面是 Python 3.7 的 tuple 源码
tupleobject.h: https://github.com/python/cpython/blob/3d75bd15ac82575967db367c517d7e6e703a6de3/Include/tupleobject.h#L25
tupleobject.c:https://github.com/python/cpython/blob/3d75bd15ac82575967db367c517d7e6e703a6de3/Objects/tupleobject.c#L16
tuple本质也是一个 array,但是空间大小固定。不同于一般 array,Python 的 tuple 做了许多优化,来提升在程序中的效率。当 tuple 的大小不超过 20 时,Python 就会把它缓存在内部的一个 free list 中。这样,如果你以后需要再去创建同样的 tuple,Python 就可以直接从缓存中载入,提高了程序运行效率。
全局变量的修改
- 当全局变量指向的对象不可变时,比如是整型、字符串等等,如果你尝试在函数内部改变它的值,却不加关键字 global,就会抛出异常:
1
2
3
4
5
6
7
8
9x = 1
def func():
x += 1
func()
x
## 输出
UnboundLocalError: local variable 'x' referenced before assignment - 如果全局变量指向的对象是可变的,比如是列表、字典等等,你就可以在函数内部修改它了:当然,需要注意的是,这里的x.append(2),并没有改变变量 x,x 依然指向原来的列表。事实上,这句话的意思是,访问 x 指向的列表,并在这个列表的末尾增加 2。
1
2
3
4
5
6
7
8
9x = [1]
def func():
x.append(2)
func()
x
## 输出
[1, 2]
进阶篇
Python对象的比较、拷贝
‘==’ VS ‘is’ 等于(==)和 is 是 Python 中对象比较常用的两种方式。简单来说,’==’操作符比较对象之间的值是否相等;而’is’操作符比较的是对象的身份标识是否相等,即它们是否是同一个对象,是否指向同一个内存地址。
1
2
3
4
5
6
7
8
9
10
11
12
13
14a = 10
b = 10
a == b
True
id(a)
4427562448
id(b)
4427562448
a is b
True首先 Python 会为 10 这个值开辟一块内存,然后变量 a 和 b 同时指向这块内存区域,即 a 和 b 都是指向 10 这个变量,因此 a 和 b 的值相等,id 也相等,a == b和a is b都返回 True。不过,需要注意,对于整型数字来说,以上a is b为 True 的结论,只适用于 -5 到 256 范围内的数字
事实上,出于对性能优化的考虑,Python 内部会对 -5 到 256 的整型维持一个数组,起到一个缓存的作用。这样,每次你试图创建一个 -5 到 256 范围内的整型数字时,Python 都会从这个数组中返回相对应的引用,而不是重新开辟一块新的内存空间。比较操作符’is’的速度效率,通常要优于’==’ 因为’is’操作符不能被重载,这样,Python 就不需要去寻找,程序中是否有其他地方重载了比较操作符,并去调用。执行比较操作符’is’,就仅仅是比较两个变量的 ID 而已。但是’==’操作符却不同,执行a == b相当于是去执行a.eq(b),而 Python 大部分的数据类型都会去重载__eq__这个函数,其内部的处理通常会复杂一些。比如,对于列表,__eq__函数会去遍历列表中的元素,比较它们的顺序和值是否相等。
浅拷贝(shallow copy)常见的浅拷贝的方法,是使用数据类型本身的构造器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23l1 = [1, 2, 3]
l2 = list(l1)
l2
[1, 2, 3]
l1 == l2
True
l1 is l2
False
s1 = set([1, 2, 3])
s2 = set(s1)
s2
{1, 2, 3}
s1 == s2
True
s1 is s2
Falsel2 就是 l1 的浅拷贝,s2 是 s1 的浅拷贝。当然,对于可变的序列,我们还可以通过切片操作符’:’完成浅拷贝
1
2
3
4
5
6
7
8l1 = [1, 2, 3]
l2 = l1[:]
l1 == l2
True
l1 is l2
False当然,Python 中也提供了相对应的函数 copy.copy(),适用于任何数据类型:
1
2
3import copy
l1 = [1, 2, 3]
l2 = copy.copy(l1)不过,需要注意的是,对于元组,使用 tuple() 或者切片操作符’:’不会创建一份浅拷贝,相反,它会返回一个指向相同元组的引用:
1
2
3
4
5
6
7
8t1 = (1, 2, 3)
t2 = tuple(t1)
t1 == t2
True
t1 is t2
True浅拷贝,是指重新分配一块内存,创建一个新的对象,里面的元素是原对象中子对象的引用。因此,如果原对象中的元素不可变,那倒无所谓;但如果元素可变,浅拷贝通常会带来一些副作用,尤其需要注意
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17l1 = [[1, 2], (30, 40)]
l2 = list(l1)
l1.append(100)
l1[0].append(3)
l1
[[1, 2, 3], (30, 40), 100]
l2
[[1, 2, 3], (30, 40)]
l1[1] += (50, 60)
l1
[[1, 2, 3], (30, 40, 50, 60), 100]
l2
[[1, 2, 3], (30, 40)]l1.append(100),表示对 l1 的列表新增元素 100。这个操作不会对 l2 产生任何影响,因为 l2 和 l1 作为整体是两个不同的对象,并不共享内存地址。再来看,l1[0].append(3),这里表示对 l1 中的第一个列表新增元素 3。因为 l2 是 l1 的浅拷贝,l2 中的第一个元素和 l1 中的第一个元素,共同指向同一个列表,因此 l2 中的第一个列表也会相对应的新增元素 3。操作后 l1 和 l2 都会改变。最后是l1[1] += (50, 60),因为元组是不可变的,这里表示对 l1 中的第二个元组拼接,然后重新创建了一个新元组作为 l1 中的第二个元素,而 l2 中没有引用新元组,因此 l2 并不受影响。操作后 l2 不变,l1 发生改变
深度拷贝,是指重新分配一块内存,创建一个新的对象,并且将原对象中的元素,以递归的方式,通过创建新的子对象拷贝到新对象中。因此,新对象和原对象没有任何关联。深度拷贝也不是完美的,往往也会带来一系列问题。如果被拷贝对象中存在指向自身的引用,那么程序很容易陷入无限循环
RecursionError: maximum recursion depth exceeded in comparison
1
2
3
4
5
6
7
8import copy
x = [1]
x.append(x)
y = copy.deepcopy(x)
# 以下命令的输出是?
x == y列表 self append 无限嵌套的原理
- x 指向一个列表,列表的第一个元素为 1;执行了 append 操作后,第二个元素又反过来指向 x,即指向了 x 所指向的列表,因此形成了一个无限嵌套的循环:[1, [1, [1, [1, …]]]]。
- 虽然 x 是无限嵌套的列表,但 x.append(x) 的操作,并不会递归遍历其中的每一个元素。它只是扩充了原列表的第二个元素,并将其指向 x,因此不会出现 stack overflow 的问题,自然不会报错。
- 为什么 len(x) 返回的是 2?我们还是来看 x,虽然它是无限嵌套的列表,但 x 的 top level 只有 2 个元素组成,第一个元素为 1,第二个元素为指向自身的列表,因此 len(x) 返回 2。
值传递
所谓值传递,通常就是拷贝参数的值,然后传递给函数里的新变量。
所谓引用传递,通常是指把参数的引用传给新的变量,这样,原变量和新变量就会指向同一块内存地址。如果改变了其中任何一个变量的值,那么另外一个变量也会相应地随之改变。
Python 的数据类型,例如整型(int)、字符串(string)等等,是不可变的。所以,a = a + 1,并不是让 a 的值增加 1,而是表示重新创建了一个新的值为 2 的对象,并让 a 指向它。但是 b 仍然不变,仍然指向 1 这个对象。
由于列表是可变的,所以 l1.append(4) 不会创建新的列表,只是在原列表的末尾插入了元素 4,变成 [1, 2, 3, 4]。由于 l1 和 l2 同时指向这个列表,所以列表的变化会同时反映在 l1 和 l2 这两个变量上,那么,l1 和 l2 的值就同时变为了 [1, 2, 3, 4]。
需要注意的是,Python 里的变量可以被删除,但是对象无法被删除。比如下面的代码:
1
2l = [1, 2, 3]
del ldel l 删除了 l 这个变量,从此以后你无法访问 l,但是对象 [1, 2, 3] 仍然存在。Python 程序运行时,其自带的垃圾回收系统会跟踪每个对象的引用。如果 [1, 2, 3] 除了 l 外,还在其他地方被引用,那就不会被回收,反之则会被回收。
变量的赋值,只是表示让变量指向了某个对象,并不表示拷贝对象给变量;而一个对象,可以被多个变量所指向。
可变对象(列表,字典,集合等等)的改变,会影响所有指向该对象的变量。
对于不可变对象(字符串,整型,元祖等等),所有指向该对象的变量的值总是一样的,也不会改变。但是通过某些操作(+= 等等)更新不可变对象的值时,会返回一个新的对象。
变量可以被删除,但是对象无法被删除。
Python 的参数传递是赋值传递 (pass by assignment),或者叫作对象的引用传递(pass by object reference)。Python 里所有的数据类型都是对象,所以参数传递时,只是让新变量与原变量指向相同的对象而已,并不存在值传递或是引用传递一说。
当可变对象当作参数传入函数里的时候,改变可变对象的值,就会影响所有指向它的变量。比如下面的例子:
1
2
3
4
5
6
7
8
9
10
11
12def my_func3(l2):
l2.append(4)
print("l2 id is {}".format(id(l2)))
l1 = [1, 2, 3]
print("l1 id is {}".format(id(l1)))
my_func3(l1)
# output
l1 id is 4358387328
l2 id is 4358387328这里 l1 和 l2 先是同时指向值为 [1, 2, 3] 的列表。不过,由于列表可变,执行 append() 函数,对其末尾加入新元素 4 时,变量 l1 和 l2 的值也都随之改变了。
但是,下面这个例子,看似都是给列表增加了一个新元素,却得到了明显不同的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def my_func3(l2):
print("before joint l2 id is {}".format(id(l2)))
l2 = l2 + [4]
print("after joint l2 id is {}".format(id(l2)))
l1 = [1, 2, 3]
print("l1 id is {}".format(id(l1)))
my_func3(l1)
# output
l1 id is 4448097856
before joint l2 id is 4448097856
after joint l2 id is 4448100544要注意,这里 l2 = l2 + [4],表示拼接两个 List,返回一个新的 List。这个过程与 l1 无关,l1还是引用的原值。
Python 中参数的传递既不是值传递,也不是引用传递,而是赋值传递,或者是叫对象的引用传递。需要注意的是,这里的赋值或对象的引用传递,不是指向一个具体的内存地址,而是指向一个具体的对象。
如果对象是可变的,当其改变时,所有指向这个对象的变量都会改变。
如果对象不可变,简单的赋值只能改变其中一个变量的值,其余变量则不受影响。
如果你想通过一个函数来改变某个变量的值,通常有两种方法。一种是直接将可变数据类型(比如列表,字典,集合)当作参数传入,直接在其上修改;第二种则是创建一个新变量,来保存修改后的值,然后将其返回给原变量。在实际工作中,我们更倾向于使用后者,因为其表达清晰明了,不易出错。
装饰器 decorator
所谓的装饰器,其实就是通过装饰器函数,来修改原函数的一些功能,使得原函数不需要修改。
Decorators is to modify the behavior of the function through a wrapper so we don’t have to actually modify the function.
- 函数的返回值也可以是函数对象(闭包)这里函数 func_closure() 的返回值是函数对象 get_message() 本身
1
2
3
4
5
6
7
8
9
10def func_closure():
def get_message(message):
print('Got a message: {}'.format(message))
return get_message
send_message = func_closure()
send_message('hello world')
# 输出
Got a message: hello world - 我们通常使用内置的装饰器@functools.wrap,它会帮助保留原函数的元信息(也就是将原函数的元信息,拷贝到对应的装饰器函数里)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import functools
def my_decorator(func):
def wrapper(*args, **kwargs):
print('wrapper of decorator')
func(*args, **kwargs)
return wrapper
def greet(message):
print(message)
greet.__name__
# 输出
'greet' - 类也可以作为装饰器。类装饰器主要依赖于函数__call_(),每当你调用一个类的示例时,函数__call__()就会被执行一次。
- 装饰器的嵌套
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
def func():
...
# 它的执行顺序从里到外,所以上面的语句也等效于下面这行代码:
decorator1(decorator2(decorator3(func)))
# 'hello world'这个例子,就可以改写成下面这样:
import functools
def my_decorator1(func):
def wrapper(*args, **kwargs):
print('execute decorator1')
func(*args, **kwargs)
return wrapper
def my_decorator2(func):
def wrapper(*args, **kwargs):
print('execute decorator2')
func(*args, **kwargs)
return wrapper
def greet(message):
print(message)
greet('hello world')
# 输出
execute decorator1
execute decorator2
hello world - 装饰器用法实例
身份认证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import functools
def authenticate(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
request = args[0]
if check_user_logged_in(request): # 如果用户处于登录状态
return func(*args, **kwargs) # 执行函数 post_comment()
else:
raise Exception('Authentication failed')
return wrapper
@authenticate
def post_comment(request, ...)
...日志记录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import time
import functools
def log_execution_time(func):
def wrapper(*args, **kwargs):
start = time.perf_counter()
res = func(*args, **kwargs)
end = time.perf_counter()
print('{} took {} ms'.format(func.__name__, (end - start) * 1000))
return res
return wrapper
def calculate_similarity(items):
...输入合理性检查
1
2
3
4
5
6
7
8
9
10import functools
def validation_check(input):
def wrapper(*args, **kwargs):
... # 检查输入是否合法
def neural_network_training(param1, param2, ...):
...缓存 LRU cache,在 Python 中的表示形式是@lru_cache。@lru_cache会缓存进程中的函数参数和结果,当缓存满了以后,会删除 least recenly used 的数据。
1
2
3
def check(param1, param2, ...) # 检查用户设备类型,版本号等等
...
metaclass
事实上,meta-class 的 meta 这个词根,起源于希腊语词汇 meta,包含下面两种意思:
“Beyond”,例如技术词汇 metadata,意思是描述数据的超越数据;
“Change”,例如技术词汇 metamorphosis,意思是改变的形态。
metaclass,一如其名,实际上同时包含了“超越类”和“变形类”的含义,完全不是“基本类”的意思。所以,要深入理解 metaclass,我们就要围绕它的超越变形特性。所有的 Python 的用户定义类,都是 type 这个类的实例。
用户自定义类,只不过是 type 类的__call__运算符重载。
metaclass 是 type 的子类,通过替换 type 的__call__运算符重载机制,“超越变形”正常的类。
迭代器和生成器
在 Python 中一切皆对象,对象的抽象就是类,而对象的集合就是容器。列表(list: [0, 1, 2]),元组(tuple: (0, 1, 2)),字典(dict: {0:0, 1:1, 2:2}),集合(set: set([0, 1, 2]))都是容器。
严谨地说,迭代器(iterator)提供了一个 next 的方法。调用这个方法后,你要么得到这个容器的下一个对象,要么得到一个 StopIteration 的错误。你不需要像列表一样指定元素的索引,因为字典和集合这样的容器并没有索引一说。比如,字典采用哈希表实现,那么你就只需要知道,next 函数可以不重复不遗漏地一个一个拿到所有元素即可。
生成器是懒人版本的迭代器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29def test_iterator():
show_memory_info('initing iterator')
list_1 = [i for i in range(100000000)]
show_memory_info('after iterator initiated')
print(sum(list_1))
show_memory_info('after sum called')
def test_generator():
show_memory_info('initing generator')
list_2 = (i for i in range(100000000))
show_memory_info('after generator initiated')
print(sum(list_2))
show_memory_info('after sum called')
%time test_iterator()
%time test_generator()
########## 输出 ##########
initing iterator memory used: 48.9765625 MB
after iterator initiated memory used: 3920.30078125 MB
4999999950000000
after sum called memory used: 3920.3046875 MB
Wall time: 17 s
initing generator memory used: 50.359375 MB
after generator initiated memory used: 50.359375 MB
4999999950000000
after sum called memory used: 50.109375 MB
Wall time: 12.5 s在你调用 next() 函数的时候,才会生成下一个变量。生成器在 Python 的写法是用小括号括起来,(i for i in range(100000000)),即初始化了一个生成器。生成器并不会像迭代器一样占用大量内存,只有在被使用的时候才会调用。而且生成器在初始化的时候,并不需要运行一次生成操作,相比于 test_iterator() ,test_generator() 函数节省了一次生成一亿个元素的过程,因此耗时明显比迭代器短。
yield 是魔术的关键。可以理解为,函数运行到这一行的时候,程序会从这里暂停,然后跳出到 next() 函数。那么 yield i ** k 是干什么的呢?它其实成了 next() 函数的返回值。
迭代器是一个有限集合,生成器则可以成为一个无限集。
给定一个 list 和一个指定数字,求这个数字在 list 中的位置。
1
2
3
4
5
6
7
8
9
10def index_generator(L, target):
for i, num in enumerate(L):
if num == target:
yield i
print(list(index_generator([1, 6, 2, 4, 5, 2, 8, 6, 3, 2], 2)))
########## 输出 ##########
[2, 5, 9]唯一需要强调的是, index_generator 会返回一个 Generator 对象,需要使用 list 转换为列表后,才能用 print 输出。
给定两个序列,判定第一个是不是第二个的子序列。(LeetCode 链接如下:https://leetcode.com/problems/is-subsequence/ )
1
2
3
4
5
6
7
8
9
10
11def is_subsequence(a, b):
b = iter(b)
return all(i in b for i in a)
print(is_subsequence([1, 3, 5], [1, 2, 3, 4, 5]))
print(is_subsequence([1, 4, 3], [1, 2, 3, 4, 5]))
########## 输出 ##########
True
False这里的(i in b),大致等价于下面这段代码:
1
2
3
4while True:
val = next(b)
if val == i:
yield True这里非常巧妙地利用生成器的特性,next() 函数运行的时候,保存了当前的指针。
容器是可迭代对象,可迭代对象调用 iter() 函数,可以得到一个迭代器。迭代器可以通过 next() 函数来得到下一个元素,从而支持遍历。
生成器是一种特殊的迭代器(注意这个逻辑关系反之不成立)。使用生成器,你可以写出来更加清晰的代码;合理使用生成器,可以降低内存占用、优化程序结构、提高程序速度。
生成器在 Python 2 的版本上,是协程的一种重要实现方式;而 Python 3.5 引入 async await 语法糖后,生成器实现协程的方式就已经落后了。我们会在下节课,继续深入讲解 Python 协程。
协程 asyncio
- 协程和多线程的区别,主要在于两点,一是协程为单线程;二是协程由用户决定,在哪些地方交出控制权,切换到下一个任务。
- 协程的写法更加简洁清晰,把 async / await 语法和 create_task 结合来用,对于中小级别的并发需求已经毫无压力。
- 写协程程序的时候,你的脑海中要有清晰的事件循环概念,知道程序在什么时候需要暂停、等待 I/O,什么时候需要一并执行到底。
1 | import asyncio |
async 修饰词声明异步函数,于是,这里的 crawl_page 和 main 都变成了异步函数。而调用异步函数,我们便可得到一个协程对象(coroutine object)。
await 是同步调用,因此, crawl_page(url) 在当前的调用结束之前,是不会触发下一次调用的。于是,这个代码效果就和上面完全一样了,相当于我们用异步接口写了个同步代码。
- 执行协程有三种方法:
- 首先,我们可以通过 await 来调用。await 执行的效果,和 Python 正常执行是一样的,也就是说程序会阻塞在这里,进入被调用的协程函数,执行完毕返回后再继续,而这也是 await 的字面意思
- 其次,我们可以通过 asyncio.create_task() 来创建任务
- 最后,我们需要 asyncio.run 来触发运行。asyncio.run 这个函数是 Python 3.7 之后才有的特性,可以让 Python 的协程接口变得非常简单,你不用去理会事件循环怎么定义和怎么使用的问题(我们会在下面讲)。一个非常好的编程规范是,asyncio.run(main()) 作为主程序的入口函数,在程序运行周期内,只调用一次 asyncio.run。
通过 asyncio.create_task 来创建任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import asyncio
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
tasks = [asyncio.create_task(crawl_page(url)) for url in urls]
for task in tasks:
await task
asyncio.run(main(['url_1', 'url_2', 'url_3', 'url_4']))对于执行 tasks,还有另一种做法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import asyncio
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
tasks = [asyncio.create_task(crawl_page(url)) for url in urls]
await asyncio.gather(*tasks)
%time asyncio.run(main(['url_1', 'url_2', 'url_3', 'url_4']))
########## 输出 ##########
crawling url_1
crawling url_2
crawling url_3
crawling url_4
OK url_1
OK url_2
OK url_3
OK url_4
Wall time: 4.01 s唯一要注意的是,*tasks 解包列表,将列表变成了函数的参数;与之对应的是, ** dict 将字典变成了函数的参数。
asyncio.create_task,asyncio.run 这些函数都是 Python 3.7 以上的版本才提供的,自然,相比于旧接口它们也更容易理解和阅读。解密协程运行时
顺序执行的时候1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import asyncio
async def worker_1():
print('worker_1 start')
await asyncio.sleep(1)
print('worker_1 done')
async def worker_2():
print('worker_2 start')
await asyncio.sleep(2)
print('worker_2 done')
async def main():
print('before await')
await worker_1()
print('awaited worker_1')
await worker_2()
print('awaited worker_2')
%time asyncio.run(main())
########## 输出 ##########
before await
worker_1 start
worker_1 done
awaited worker_1
worker_2 start
worker_2 done
awaited worker_2
Wall time: 3 s并发执行的时候
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import asyncio
async def worker_1():
print('worker_1 start')
await asyncio.sleep(1)
print('worker_1 done')
async def worker_2():
print('worker_2 start')
await asyncio.sleep(2)
print('worker_2 done')
async def main():
task1 = asyncio.create_task(worker_1())
task2 = asyncio.create_task(worker_2())
print('before await')
await task1
print('awaited worker_1')
await task2
print('awaited worker_2')
%time asyncio.run(main())
########## 输出 ##########
before await
worker_1 start
worker_2 start
worker_1 done
awaited worker_1
worker_2 done
awaited worker_2
Wall time: 2.01 s为了更详细了解到协程和线程的具体区别,这里详细地分析了整个过程。步骤有点多,别着急,慢慢来看。
- asyncio.run(main()),程序进入 main() 函数,事件循环开启;
- task1 和 task2 任务被创建,并进入事件循环等待运行;运行到 print,输出 ‘before await’;
- await task1 执行,用户选择从当前的主任务中切出,事件调度器开始调度 worker_1;
- worker_1 开始运行,运行 print 输出’worker_1 start’,然后运行到 await asyncio.sleep(1), 从当前任务切出,事件调度器开始调度 worker_2;
- worker_2 开始运行,运行 print 输出 ‘worker_2 start’,然后运行 await asyncio.sleep(2) 从当前任务切出;
- 以上所有事件的运行时间,都应该在 1ms 到 10ms 之间,甚至可能更短,事件调度器从这个时候开始暂停调度;
- 一秒钟后,worker_1 的 sleep 完成,事件调度器将控制权重新传给 task_1,输出 ‘worker_1 done’,task_1 完成任务,从事件循环中退出;
- await task1 完成,事件调度器将控制器传给主任务,输出 ‘awaited worker_1’,·然后在 await task2 处继续等待;
- 两秒钟后,worker_2 的 sleep 完成,事件调度器将控制权重新传给 task_2,输出 ‘worker_2 done’,task_2 完成任务,从事件循环中退出;
- 主任务输出 ‘awaited worker_2’,协程全任务结束,事件循环结束。
- 如果我们想给某些协程任务限定运行时间,一旦超时就取消,又该怎么做呢?再进一步,如果某些协程运行时出现错误,又该怎么处理呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51import asyncio
from datetime import datetime
def print_time(s=""):
now = datetime.now()
current_time = now.strftime("%H:%M:%S")
print("{} Current Time ={}".format(s, current_time))
async def worker_1():
print_time("start work1")
await asyncio.sleep(1)
print_time("end work1")
return 1
async def worker_2():
print_time("start work2")
await asyncio.sleep(2)
print_time("end work2")
return 2 / 0
async def worker_3():
print_time("start work3")
await asyncio.sleep(3)
print_time("end work3")
return 3
async def main():
task_1 = asyncio.create_task(worker_1())
task_2 = asyncio.create_task(worker_2())
task_3 = asyncio.create_task(worker_3())
print_time("start work in main")
await asyncio.sleep(2)
print_time("end work in main")
task_3.cancel()
res = await asyncio.gather(task_1, task_2, task_3, return_exceptions=True)
print(res)
await asyncio.sleep(2)
########## 输出 ##########
start work in main Current Time =14:41:05
start work1 Current Time =14:41:05
start work2 Current Time =14:41:05
start work3 Current Time =14:41:05
end work1 Current Time =14:41:06
end work in main Current Time =14:41:07
end work2 Current Time =14:41:07
[1, ZeroDivisionError('division by zero'), CancelledError()]
- 从 main 函数程序入口开始,创建 3 个 task,进入事件循环等待运行。运行 await asyncio.sleep(2) 从当前主任务切出;
- 运行 task1, 又是await,切换到 task2, 还是 await, 切换到 task3,再次 await, 切回主任务。
- 一秒钟后,worker_1 的 sleep 完成,事件调度器将控制权重新传给 task_1, task1 结束。
- 两秒钟后,主程序的 sleep 完成, 取消 task_3.cancel()。
- 紧接着, task2 sleep 完成, 事件调度器将控制器 task2, task2 完成
- task3 因为已经取消了,协程全任务结束,事件循环结束。
- 最后打印出结果,很稳
worker_1 正常运行,worker_2 运行中出现错误,worker_3 执行时间过长被我们 cancel 掉了,这些信息会全部体现在最终的返回结果 res 中。不过要注意return_exceptions=True这行代码。如果不设置这个参数,错误就会完整地 throw 到我们这个执行层,从而需要 try except 来捕捉,这也就意味着其他还没被执行的任务会被全部取消掉。为了避免这个局面,我们将 return_exceptions 设置为 True 即可。
- 用协程来实现一个经典的生产者消费者模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93import asyncio
async def worker_1():
await asyncio.sleep(1)
return 1
async def worker_2():
await asyncio.sleep(2)
return 2 / 0
async def worker_3():
await asyncio.sleep(3)
return 3
async def main():
task_1 = asyncio.create_task(worker_1())
task_2 = asyncio.create_task(worker_2())
task_3 = asyncio.create_task(worker_3())
await asyncio.sleep(2)
task_3.cancel()
res = await asyncio.gather(task_1, task_2, task_3, return_exceptions=True)
print(res)
%time asyncio.run(main())
########## 输出 ##########
[1, ZeroDivisionError('division by zero'), CancelledError()]
Wall time: 2 s
你可以看到,worker_1 正常运行,worker_2 运行中出现错误,worker_3 执行时间过长被我们 cancel 掉了,这些信息会全部体现在最终的返回结果 res 中。
不过要注意return_exceptions=True这行代码。如果不设置这个参数,错误就会完整地 throw 到我们这个执行层,从而需要 try except 来捕捉,这也就意味着其他还没被执行的任务会被全部取消掉。为了避免这个局面,我们将 return_exceptions 设置为 True 即可。
到这里,发现了没,线程能实现的,协程都能做到。那就让我们温习一下这些知识点,用协程来实现一个经典的生产者消费者模型吧。
import asyncio
import random
async def consumer(queue, id):
while True:
val = await queue.get()
print('{} get a val: {}'.format(id, val))
await asyncio.sleep(1)
async def producer(queue, id):
for i in range(5):
val = random.randint(1, 10)
await queue.put(val)
print('{} put a val: {}'.format(id, val))
await asyncio.sleep(1)
async def main():
queue = asyncio.Queue()
consumer_1 = asyncio.create_task(consumer(queue, 'consumer_1'))
consumer_2 = asyncio.create_task(consumer(queue, 'consumer_2'))
producer_1 = asyncio.create_task(producer(queue, 'producer_1'))
producer_2 = asyncio.create_task(producer(queue, 'producer_2'))
await asyncio.sleep(10)
consumer_1.cancel()
consumer_2.cancel()
await asyncio.gather(consumer_1, consumer_2, producer_1, producer_2, return_exceptions=True)
%time asyncio.run(main())
########## 输出 ##########
producer_1 put a val: 5
producer_2 put a val: 3
consumer_1 get a val: 5
consumer_2 get a val: 3
producer_1 put a val: 1
producer_2 put a val: 3
consumer_2 get a val: 1
consumer_1 get a val: 3
producer_1 put a val: 6
producer_2 put a val: 10
consumer_1 get a val: 6
consumer_2 get a val: 10
producer_1 put a val: 4
producer_2 put a val: 5
consumer_2 get a val: 4
consumer_1 get a val: 5
producer_1 put a val: 2
producer_2 put a val: 8
consumer_1 get a val: 2
consumer_2 get a val: 8
Wall time: 10 s
并发编程之Futures
并发,通过线程和任务之间互相切换的方式实现,但同一时刻,只允许有一个线程或任务执行。并发通常应用于 I/O 操作频繁的场景,比如你要从网站上下载多个文件,I/O 操作的时间可能会比 CPU 运行处理的时间长得多。
而并行,则是指多个进程完全同步同时的执行。并行则更多应用于 CPU heavy 的场景,比如 MapReduce 中的并行计算,为了加快运行速度,一般会用多台机器、多个处理器来完成。
在 Python 中,并发并不是指同一时刻有多个操作(thread、task)同时进行。相反,某个特定的时刻,它只允许有一个操作发生,只不过线程 / 任务之间会互相切换,直到完成。
对于 threading,操作系统知道每个线程的所有信息,因此它会做主在适当的时候做线程切换。很显然,这样的好处是代码容易书写,因为程序员不需要做任何切换操作的处理;但是切换线程的操作,也有可能出现在一个语句执行的过程中(比如 x += 1),这样就容易出现 race condition 的情况。
对于 asyncio,主程序想要切换任务时,必须得到此任务可以被切换的通知,这样一来也就可以避免刚刚提到的 race condition 的情况。
所谓的并行,指的才是同一时刻、同时发生。Python 中的 multi-processing 便是这个意思,对于 multi-processing,你可以简单地这么理解:比如你的电脑是 6 核处理器,那么在运行程序时,就可以强制 Python 开 6 个进程,同时执行,以加快运行速度
我们具体来看这段代码,它是多线程版本和单线程版的主要区别所在:
1
2with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_one, sites)我们创建了一个线程池,总共有 5 个线程可以分配使用。executer.map() 与前面所讲的 Python 内置的 map() 函数类似,表示对 sites 中的每一个元素,并发地调用函数 download_one()。顺便提一下,在 download_one() 函数中,我们使用的 requests.get() 方法是线程安全的(thread-safe),因此在多线程的环境下,它也可以安全使用,并不会出现 race condition 的情况。
我们也可以用并行的方式去提高程序运行效率。你只需要在 download_all() 函数中,做出下面的变化即可:
1
2
3with futures.ThreadPoolExecutor(workers) as executor
=>
with futures.ProcessPoolExecutor() as executor:在需要修改的这部分代码中,函数 ProcessPoolExecutor() 表示创建进程池,使用多个进程并行的执行程序。不过,这里我们通常省略参数 workers,因为系统会自动返回 CPU 的数量作为可以调用的进程数。
到底什么是 Futures
Python 中的 Futures 模块,位于 concurrent.futures 和 asyncio 中,它们都表示带有延迟的操作。Futures 会将处于等待状态的操作包裹起来放到队列中,这些操作的状态随时可以查询,当然,它们的结果或是异常,也能够在操作完成后被获取。Futures 中的 Executor 类,当我们执行 executor.submit(func) 时,它便会安排里面的 func() 函数执行,并返回创建好的 future 实例,以便你之后查询调用。Futures 中的方法 done(),表示相对应的操作是否完成——True 表示完成,False 表示没有完成。不过,要注意,done() 是 non-blocking 的,会立即返回结果。相对应的 add_done_callback(fn),则表示 Futures 完成后,相对应的参数函数 fn,会被通知并执行调用。
Futures 中还有一个重要的函数 result(),它表示当 future 完成后,返回其对应的结果或异常。而 as_completed(fs),则是针对给定的 future 迭代器 fs,在其完成后,返回完成后的迭代器。
1 | import concurrent.futures |
这里,我们首先调用 executor.submit(),将下载每一个网站的内容都放进 future 队列 to_do,等待执行。然后是 as_completed() 函数,在 future 完成后,便输出结果。
不过,这里要注意,future 列表中每个 future 完成的顺序,和它在列表中的顺序并不一定完全一致。到底哪个先完成、哪个后完成,取决于系统的调度和每个 future 的执行时间。
- 为什么多线程每次只能有一个线程执行?
同一时刻,Python 主程序只允许有一个线程执行,所以 Python 的并发,是通过多线程的切换完成的。Python 的解释器并不是线程安全的,为了解决由此带来的 race condition 等问题,Python 便引入了全局解释器锁,也就是同一时刻,只允许一个线程执行。当然,在执行 I/O 操作时,如果一个线程被 block 了,全局解释器锁便会被释放,从而让另一个线程能够继续执行。
并发编程之Asyncio
在处理 I/O 操作时,使用多线程与普通的单线程相比,效率得到了极大的提高。你可能会想,既然这样,为什么还需要 Asyncio?
- 比如,多线程运行过程容易被打断,因此有可能出现 race condition 的情况;
- 再如,线程切换本身存在一定的损耗,线程数不能无限增加,因此,如果你的 I/O 操作非常 heavy,多线程很有可能满足不了高效率、高质量的需求。
Sync VS Async
所谓 Sync,是指操作一个接一个地执行,下一个操作必须等上一个操作完成后才能执行。
而 Async 是指不同操作间可以相互交替执行,如果其中的某个操作被 block 了,程序并不会等待,而是会找出可执行的操作继续执行。
事实上,Asyncio 和其他 Python 程序一样,是单线程的,它只有一个主线程,但是可以进行多个不同的任务(task),这里的任务,就是特殊的 future 对象。这些不同的任务,被一个叫做 event loop 的对象所控制。你可以把这里的任务,类比成多线程版本里的多个线程。
为了简化讲解这个问题,我们可以假设任务只有两个状态:一是预备状态;二是等待状态。所谓的预备状态,是指任务目前空闲,但随时待命准备运行。而等待状态,是指任务已经运行,但正在等待外部的操作完成,比如 I/O 操作。
在这种情况下,event loop 会维护两个任务列表,分别对应这两种状态;并且选取预备状态的一个任务(具体选取哪个任务,和其等待的时间长短、占用的资源等等相关),使其运行,一直到这个任务把控制权交还给 event loop 为止。
当任务把控制权交还给 event loop 时,event loop 会根据其是否完成,把任务放到预备或等待状态的列表,然后遍历等待状态列表的任务,查看他们是否完成。
如果完成,则将其放到预备状态的列表;如果未完成,则继续放在等待状态的列表。这样,当所有任务被重新放置在合适的列表后,新一轮的循环又开始了:event loop 继续从预备状态的列表中选取一个任务使其执行…如此周而复始,直到所有任务完成。值得一提的是,对于 Asyncio 来说,它的任务在运行时不会被外部的一些因素打断,因此 Asyncio 内的操作不会出现 race condition 的情况,这样你就不需要担心线程安全的问题了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38import asyncio
import aiohttp
import time
async def download_one(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
print('Read {} from {}'.format(resp.content_length, url))
async def download_all(sites):
tasks = [asyncio.create_task(download_one(site)) for site in sites]
await asyncio.gather(*tasks)
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
asyncio.run(download_all(sites))
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time))
if __name__ == '__main__':
main()这里的 Async 和 await 关键字是 Asyncio 的最新写法,表示这个语句 / 函数是 non-block 的,正好对应前面所讲的 event loop 的概念。如果任务执行的过程需要等待,则将其放入等待状态的列表中,然后继续执行预备状态列表里的任务。
主函数里的 asyncio.run(coro) 是 Asyncio 的 root call,表示拿到 event loop,运行输入的 coro,直到它结束,最后关闭这个 event loop。事实上,asyncio.run() 是 Python3.7+ 才引入的
这里的asyncio.create_task(coro),表示对输入的协程 coro 创建一个任务,安排它的执行,并返回此任务对象。这个函数也是 Python 3.7+ 新增的,如果是之前的版本,你可以用asyncio.ensure_future(coro)等效替代。可以看到,这里我们对每一个网站的下载,都创建了一个对应的任务。
asyncio.gather(*aws, loop=None, return_exception=False),则表示在 event loop 中运行aws序列的所有任务。当然,除了例子中用到的这几个函数,Asyncio 还提供了很多其他的用法,你可以查看 相应文档 进行了解。
Asyncio 有缺陷吗?想用好 Asyncio,特别是发挥其强大的功能,很多情况下必须得有相应的 Python 库支持。
多线程还是 Asyncio, 总的来说,你可以遵循以下伪代码的规范:
1
2
3
4
5
6
7if io_bound:
if io_slow:
print('Use Asyncio')
else:
print('Use multi-threading')
else if cpu_bound:
print('Use multi-processing')如果是 I/O bound,并且 I/O 操作很慢,需要很多任务 / 线程协同实现,那么使用 Asyncio 更合适。
如果是 I/O bound,但是 I/O 操作很快,只需要有限数量的任务 / 线程,那么使用多线程就可以了。
如果是 CPU bound,则需要使用多进程来提高程序运行效率。
Python GIL(全局解释器锁)
- Python 的线程,的的确确封装了底层的操作系统线程,在 Linux 系统里是 Pthread(全称为 POSIX Thread),而在 Windows 系统里是 Windows Thread。另外,Python 的线程,也完全受操作系统管理,比如协调何时执行、管理内存资源、管理中断等等。所以,虽然 Python 的线程和 C++ 的线程本质上是不同的抽象,但它们的底层并没有什么不同。
- GIL,是最流行的 Python 解释器 CPython 中的一个技术术语。它的意思是全局解释器锁,本质上是类似操作系统的 Mutex。每一个 Python 线程,在 CPython 解释器中执行时,都会先锁住自己的线程,阻止别的线程执行。当然,CPython 会做一些小把戏,轮流执行 Python 线程。这样一来,用户看到的就是“伪并行”——Python 线程在交错执行,来模拟真正并行的线程。
- CPython 使用引用计数来管理内存,所有 Python 脚本中创建的实例,都会有一个引用计数,来记录有多少个指针指向它。当引用计数只有 0 时,则会自动释放内存。这个例子中,a 的引用计数是 3,因为有 a、b 和作为参数传递的 getrefcount 这三个地方,都引用了一个空列表。
1
2
3
4
5import sys
a = []
b = a
sys.getrefcount(a)
3 - CPython 引进 GIL 其实主要就是这么两个原因:一是设计者为了规避类似于内存管理这样的复杂的竞争风险问题(race condition);二是因为 CPython 大量使用 C 语言库,但大部分 C 语言库都不是原生线程安全的(线程安全会降低性能和增加复杂度)。
- GIL 是如何工作的: 一个 GIL 在 Python 程序的工作示例。其中,Thread 1、2、3 轮流执行,每一个线程在开始执行时,都会锁住 GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放 GIL,以允许别的线程开始利用资源。
- 为什么 Python 线程会去主动释放 GIL 呢?CPython 中还有另一个机制,叫做 check_interval,意思是 CPython 解释器会去轮询检查线程 GIL 的锁住情况。每隔一段时间,Python 解释器就会强制当前线程去释放 GIL,这样别的线程才能有执行的机会。不同版本的 Python 中,check interval 的实现方式并不一样。早期的 Python 是 100 个 ticks,大致对应了 1000 个 bytecodes;而 Python 3 以后,interval 是 15 毫秒。当然,我们不必细究具体多久会强制释放 GIL,这不应该成为我们程序设计的依赖条件,我们只需明白,CPython 解释器会在一个“合理”的时间范围内释放 GIL 就可以了。
- GIL 的设计,主要是为了方便 CPython 解释器层面的编写者,而不是 Python 应用层面的程序员。作为 Python 的使用者,我们还是需要 lock 等工具,来确保线程安全。
- 如何绕过 GIL: 1. 绕过 CPython,使用 JPython(Java 实现的 Python 解释器)等别的实现; 2. 把关键性能代码,放到别的语言(一般是 C++)中实现。
- GIL 与多线程的关系: GIL 只支持单线程,而 Python 支持多线程,这两者之间究竟是什么关系呢?
- 其实,GIL 的存在与 Python 支持多线程并不矛盾。前面我们讲过,GIL 是指同一时刻,程序只能有一个线程运行;而 Python 中的多线程,是指多个线程交替执行,造成一个“伪并行”的结果,但是具体到某一时刻,仍然只有 1 个线程在运行,并不是真正的多线程并行
- 举个例子来理解。比如,我用 10 个线程来爬取 50 个网站的内容。线程 1 在爬取第 1 个网站时,被 I/O block 住了,处于等待状态;这时,GIL 就会释放,而线程 2 就会开始执行,去爬取第 2 个网站,依次类推。等到线程 1 的 I/O 操作完成时,主程序便又会切回线程 1,让其完成剩下的操作。这样一来,从用户角度看到的,便是我们所说的多线程。
Python 垃圾回收机制
什么是内存泄漏呢?这里的泄漏,并不是说你的内存出现了信息安全问题,被恶意程序利用了,而是指程序本身没有设计好,导致程序未能释放已不再使用的内存。内存泄漏也不是指你的内存在物理上消失了,而是意味着代码在分配了某段内存后,因为设计错误,失去了对这段内存的控制,从而造成了内存的浪费。
计数引用, Python 中一切皆对象。因此,你所看到的一切变量,本质上都是对象的一个指针。当这个对象的引用计数(指针数)为 0 的时候,说明这个对象永不可达,自然它也就成为了垃圾,需要被回收。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory))
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
func()
show_memory_info('finished')
# ----------------------------------
initial memory used: 6.0625 MB
after a created memory used: 385.87890625 MB
finished memory used: 12.7421875 MB调用函数 func(),在列表 a 被创建之后,内存占用迅速增加到了 433 MB:而在函数调用结束后,内存则返回正常。函数内部声明的列表 a 是局部变量,在函数返回后,局部变量的引用会注销掉;此时,列表 a 所指代对象的引用数为 0,Python 便会执行垃圾回收,因此之前占用的大量内存就又回来了。
深入看一下 Python 内部的引用计数机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import sys
a = []
# 两次引用,一次来自 a,一次来自 getrefcount
print(sys.getrefcount(a))
def func(a):
# 四次引用,a,python 的函数调用栈,函数参数,和 getrefcount
print(sys.getrefcount(a))
func(a)
# 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在
print(sys.getrefcount(a))
########## 输出 ##########
2
4
2sys.getrefcount() 这个函数,可以查看一个变量的引用次数。这段代码本身应该很好理解,不过别忘了,getrefcount 本身也会引入一次计数。另一个要注意的是,在函数调用发生的时候,会产生额外的两次引用,一次来自函数栈,另一个是函数参数。 函数栈引用这里有点不解?
另外一个示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import sys
a = []
print(sys.getrefcount(a)) # 两次
b = a
print(sys.getrefcount(a)) # 三次
c = b
d = b
e = c
f = e
g = d
print(sys.getrefcount(a)) # 八次
########## 输出 ##########
2
3
8需要你稍微注意一下,a、b、c、d、e、f、g 这些变量全部指代的是同一个对象,而 sys.getrefcount() 函数并不是统计一个指针,而是要统计一个对象被引用的次数,所以最后一共会有八次引用。
手动释放内存,应该怎么做呢?方法同样很简单。你只需要先调用 del a 来删除一个对象;然后强制调用 gc.collect(),即可手动启动垃圾回收。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import gc
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
del a
gc.collect()
show_memory_info('finish')
print(a)
########## 输出 ##########
initial memory used: 48.1015625 MB
after a created memory used: 434.3828125 MB
finish memory used: 48.33203125 MB
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-12-153e15063d8a> in <module>
11
12 show_memory_info('finish')
---> 13 print(a)
NameError: name 'a' is not defined面试官问:引用次数为 0 是垃圾回收启动的充要条件吗?还有没有其他可能性呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')
a.append(b)
b.append(a)
func()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 47.984375 MB
after a, b created memory used: 822.73828125 MB
finished memory used: 821.73046875 MB这里,a 和 b 互相引用,并且,作为局部变量,在函数 func 调用结束后,a 和 b 这两个指针从程序意义上已经不存在了。但是,很明显,依然有内存占用!为什么呢?因为互相引用,导致它们的引用数都不为 0。更隐蔽的情况是出现一个引用环,在工程代码比较复杂的情况下,引用环还真不一定能被轻易发现。
Python 本身能够处理这种情况,我们刚刚讲过的,可以显式调用 gc.collect() ,来启动垃圾回收。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import gc
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')
a.append(b)
b.append(a)
func()
gc.collect()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 49.51171875 MB
after a, b created memory used: 824.1328125 MB
finished memory used: 49.98046875 MBPython 使用标记清除(mark-sweep)算法和分代收集(generational),来启用针对循环引用的自动垃圾回收。
先来看标记清除算法。我们先用图论来理解不可达的概念。对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点;那么,在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点。显而易见,这些节点的存在是没有任何意义的,自然的,我们就需要对它们进行垃圾回收。当然,每次都遍历全图,对于 Python 而言是一种巨大的性能浪费。所以,在 Python 的垃圾回收实现中,mark-sweep 使用双向链表维护了一个数据结构,并且只考虑容器类的对象(只有容器类对象才有可能产生循环引用)。
分代收集算法,则是另一个优化手段。Python 将所有对象分为三代。刚刚创立的对象是第 0 代;经过一次垃圾回收后,依然存在的对象,便会依次从上一代挪到下一代。而每一代启动自动垃圾回收的阈值,则是可以单独指定的。当垃圾回收器中新增对象减去删除对象达到相应的阈值时,就会对这一代对象启动垃圾回收。分代收集基于的思想是,新生的对象更有可能被垃圾回收,而存活更久的对象也有更高的概率继续存活。因此,通过这种做法,可以节约不少计算量,从而提高 Python 的性能。
调试内存泄漏: objgraph,一个非常好用的可视化引用关系的包。在这个包中,我主要推荐两个函数,第一个是 show_refs(),它可以生成清晰的引用关系图。另一个非常有用的函数,是 show_backrefs()。
多进程与多线程的应用场景
如果你想对 CPU 密集型任务加速,使用多线程是无效的,请使用多进程。这里所谓的 CPU 密集型任务,是指会消耗大量 CPU 资源的任务,比如求 1 到 100000000 的乘积,或者是把一段很长的文字编码后又解码等等。使用多线程之所以无效,原因正是我们前面刚讲过的,Python 多线程的本质是多个线程互相切换,但同一时刻仍然只允许一个线程运行。因此,你使用多线程,和使用一个主线程,本质上来说并没有什么差别;反而在很多情况下,因为线程切换带来额外损耗,还会降低程序的效率。如果使用多进程,就可以允许多个进程之间 in parallel 地执行任务,所以能够有效提高程序的运行效率。
至于 I/O 密集型任务,如果想要加速,请优先使用多线程或 Asyncio。当然,使用多进程也可以达到目的,但是完全没有这个必要。因为对 I/O 密集型任务来说,大多数时间都浪费在了 I/O 等待上。因此,在一个线程 / 任务等待 I/O 时,我们只需要切换线程 / 任务去执行其他 I/O 操作就可以了。不过,如果 I/O 操作非常多、非常 heavy,需要建立的连接也比较多时,我们一般会选择 Asyncio。因为 Asyncio 的任务切换更加轻量化,并且它能启动的任务数也远比多线程启动的线程数要多。当然,如果 I/O 的操作不是那么的 heavy,那么使用多线程也就足够了。
规范篇
代码风格
- 《8 号 Python 增强规范》(Python Enhacement Proposal #8),以下简称 PEP8;
- 《Google Python 风格规范》(Google Python Style Guide),以下简称 Google Style,这是源自 Google 内部的风格规范。公开发布的社区版本,是为了让 Google 旗下所有 Python 开源项目的编程风格统一。(http://google.github.io/styleguide/pyguide.html)
- 统一的编程规范能提高开发效率。而开发效率,关乎三类对象,也就是阅读者、编程者和机器。他们的优先级是阅读者的体验 >> 编程者的体验 >> 机器的体验。
- 对于命名原则,我想很多人应该都有所理解,PEP8 第 38 条规定命名必须有意义,不能是无意义的单字母。
- Google Style 2.2 条规定,Python 代码中的 import 对象,只能是 package 或者 module。
- 正确的是在代码风格中,当你和 None 比较时候永远使用 is, 不要忘记,Python 中还有隐式布尔转换, 当你明确想要比较对象是否是 None 时,一定要显式地用 is None。
分解代码
- PEP 是 Python Enhancement Proposal 的缩写,翻译过来叫“Python 增强规范”。正如我们写文章,会有句式、标点、段落格式、开头缩进等标准的规范一样,Python 书写自然也有一套较为官方的规范。PEP 8 就是这样一种规范,它存在的意义,就是让 Python 更易阅读,换句话,增强代码可读性。
- Pycharm 已经内置了 PEP 8 规范检测器,它会自动对编码不规范的地方进行检查,然后指出错误,并推荐修改方式
- Python 的缩进其实可以写成很多种,Tab、双空格、四空格、空格和 Tab 混合等。而 PEP 8 规范告诉我们,请选择四个空格的缩进,不要使用 Tab,更不要 Tab 和空格混着用。
- 每行最大长度请限制在 79 个字符。
- 空行规范: 全局的类和函数的上方需要空两个空行,而类的函数之间需要空一个空行。函数内部也可以使用空行,和英语的段落一样,用来区分不同意群之间的代码块。但是记住最多空一行,千万不要滥用。
- Python 本身允许把多行合并为一行,使用分号隔开,但这是 PEP 8 不推荐的做法。所以,即使是使用控制语句 if / while / for,你的执行语句哪怕只有一行命令,也请另起一行,这样可以更大程度提升阅读效率。
- 至于代码的尾部,每个代码文件的最后一行为空行,并且只有这一个空行。
- 空格规范: 函数的参数列表中,调用函数的参数列表中会出现逗号,请注意逗号后要跟一个空格,这是英语的使用习惯,也能让每个参数独立阅读,更清晰。冒号经常被用来初始化字典,冒号后面也要跟一个空格。Python 中我们可以使用#进行单独注释,请记得要在#后、注释前加一个空格。对于操作符,例如+,-,*,/,&,|,=,==,!=,请在两边都保留空格。不过与此对应,括号内的两端并不需要空格。
- 换行规范: 第一种,通过括号来将过长的运算进行封装,此时虽然跨行,但是仍处于一个逻辑引用之下。 第二种,则是通过换行符来实现。
- 文档规范: 首先,所有 import 尽量放在开头。其次,不要使用 import 一次导入多个模块。虽然我们可以在一行中 import 多个模块,并用逗号分隔,但请不要这么做。import time, os 是 PEP 8 不推荐的做法。如果你采用 from module import func 这样的语句,请确保 func 在本文件中不会出现命名冲突。不过,你其实可以通过 from module import func as new_func 来进行重命名,从而避免冲突。
- 注释规范: 对于大的逻辑块,我们可以在最开始相同的缩进处以 # 开始写注释。至于行注释,如空格规范中所讲,我们可以在一行后面跟两个空格,然后以 # 开头加入注释。不过,请注意,行注释并不是很推荐的方式。
- 文档描述: ,类和函数的注释,为的是让读者快速理解这个函数做了什么,它输入的参数和格式,输出的返回值和格式,以及其他需要注意的地方。至于 docstring 的写法,它是用三个双引号开始、三个双引号结尾。我们首先用一句话简单说明这个函数做什么,然后跟一段话来详细解释;再往后是参数列表、参数格式、返回值格式。
- 命名规范: 变量名请拒绝使用 a b c d 这样毫无意义的单字符,我们应该使用能够代表其意思的变量名,一般来说,变量使用小写,通过下划线串联起来,
- 例如:data_format、input_spec、image_data_set。唯一可以使用单字符的地方是迭代,比如 for i in range(n) 这种,为了精简可以使用。如果是类的私有变量,请记得前面增加两个下划线。
- 对于常量,最好的做法是全部大写,并通过下划线连接,例如:WAIT_TIME、SERVER_ADDRESS、PORT_NUMBER。
- 对于函数名,同样也请使用小写的方式,通过下划线连接起来,例如:launch_nuclear_missile()、check_input_validation()。
- 对于类名,则应该首字母大写,然后合并起来,例如:class SpatialDropout2D()、class FeatureSet()。
- 代码分解技巧: 编程中一个核心思想是,不写重复代码。重复代码大概率可以通过使用条件、循环、构造函数和类来解决。而另一个核心思想则是,减少迭代层数,尽可能让 Python 代码扁平化,毕竟,人的大脑无法处理过多的栈操作。
- 一个函数的粒度应该尽可能细,不要让一个函数做太多的事情。所以,对待一个复杂的函数,我们需要尽可能地把它拆分成几个功能简单的函数,然后合并起来。那么,应该如何拆分函数呢?
- 以一个简单的二分搜索来举例说明。我给定一个非递减整数数组,和一个 target,要求你找到数组中最小的一个数 x,可以满足 x*x > target。一旦不存在,则返回 -1。
1 | def solve(arr, target): |
给出的第一段代码这样的写法,在算法比赛和面试中已经 OK 了。不过,从工程角度来说,我们还能继续优化一下:
1 | def comp(x, target): |
第二段代码中,我把不同功能的代码拿了出来。其中,comp() 函数作为核心判断,拿出来后可以让整个程序更清晰;同时,我也把二分搜索的主程序拿了出来,只负责二分搜索;最后的 solve() 函数拿到结果,决定返回不存在,还是返回值。这样一来,每个函数各司其职,阅读性也能得到一定提高。
- 最后,我们再来看一下如何拆分类。老规矩,先看代码:job 在其中出现了很多次,而且它们表达的是一个意义实体,这种情况下,我们可以考虑将这部分分解出来,作为单独的类。
1
2
3
4
5
6
7
8class Person:
def __init__(self, name, sex, age, job_title, job_description, company_name):
self.name = name
self.sex = sex
self.age = age
self.job_title = job_title
self.job_description = description
self.company_name = company_name1
2
3
4
5
6
7
8
9
10
11
12
13class Person:
def __init__(self, name, sex, age, job_title, job_description, company_name):
self.name = name
self.sex = sex
self.age = age
self.job = Job(job_title, job_description, company_name)
class Job:
def __init__(self, job_title, job_description, company_name):
self.job_title = job_title
self.job_description = description
self.company_name = company_name
合理利用assert
Python 的 assert 语句,可以说是一个 debug 的好工具,主要用于测试一个条件是否满足。如果测试的条件满足,则什么也不做,相当于执行了 pass 语句;如果测试条件不满足,便会抛出异常 AssertionError,并返回具体的错误信息(optional)。它的具体语法是下面这样的:
1
2
3
4
5
6
7
8
9
10
11
12
13assert_stmt ::= "assert" expression ["," expression]
assert 1 == 2
if __debug__:
if not expression: raise AssertionError
assert 1 == 2, 'assertion is wrong'
if __debug__:
if not expression1: raise AssertionError(expression2)一定记住,不要在使用 assert 时加入括号,比如下面这个例子:
1
2
3
4assert(1 == 2, 'This should fail')
# 输出
<ipython-input-8-2c057bd7fe24>:1: SyntaxWarning: assertion is always true, perhaps remove parentheses?
assert(1 == 2, 'This should fail')在实际工作中,assert 还有一些很常见的用法,比如这里函数 func() 里的所有操作,都是基于输入必须是 list 这个前提。
1
2
3
4
5
6
7
8
9def func(input):
assert isinstance(input, list), 'input must be type of list'
# 下面的操作都是基于前提:input 必须是 list
if len(input) == 1:
...
elif len(input) == 2:
...
else:
...assert 错误示例
1
2
3
4def delete_course(user, course_id):
assert user_is_admin(user), 'user must be admin'
assert course_exist(course_id), 'course id must exist'
delete(course_id)assert 的检查是可以被关闭的,比如在运行 Python 程序时,加入-O这个选项就会让 assert 失效。一旦 assert 的检查被关闭,user_is_admin() 和 course_exist() 这两个函数便不会被执行。 任何用户都有权限删除专栏课程;并且,不管这个课程是否存在,他们都可以强行执行删除操作。
正确的做法,是使用条件语句进行相应的检查,并合理抛出异常:
1 | def delete_course(user, course_id): |
再来看一个例子,如果你想打开一个文件,进行数据读取、处理等一系列操作,那么下面这样的写法,显然也是不正确的:
1 | def read_and_process(path): |
因为 assert 的使用,表明你强行指定了文件必须存在,但事实上在很多情况下,这个假设并不成立。另外,打开文件操作,也有可能触发其他的异常。所以,正确的做法是进行异常处理,用 try 和 except 来解决:
1 | def read_and_process(path): |
- 总的来说,assert 并不适用 run-time error 的检查。assert 通常用来对代码进行必要的 self check,表明你很确定这种情况一定发生,或者一定不会发生。需要注意的是,使用 assert 时,一定不要加上括号,否则无论表达式对与错,assert 检查永远不会 fail。另外,程序中的 assert 语句,可以通过-O等选项被全局 disable。
上下文管理器
在任何一门编程语言中,文件的输入输出、数据库的连接断开等,都是很常见的资源管理操作。但资源都是有限的,在写程序时,我们必须保证这些资源在使用过后得到释放,不然就容易造成资源泄露,轻者使得系统处理缓慢,重则会使系统崩溃。
错误示例
1
2
3for x in range(10000000):
f = open('test.txt', 'w')
f.write('hello')这就是一个典型的资源泄露的例子。因为程序中同时打开了太多的文件,占据了太多的资源,造成系统崩溃。
为了解决这个问题,不同的编程语言都引入了不同的机制。而在 Python 中,对应的解决方式便是上下文管理器(context manager)。上下文管理器,能够帮助你自动分配并且释放资源,其中最典型的应用便是 with 语句。所以,上面代码的正确写法应该如下所示:1
2
3for x in range(10000000):
with open('test.txt', 'w') as f:
f.write('hello')另外一个典型的例子,是 Python 中的 threading.lock 类。举个例子,比如我想要获取一个锁,执行相应的操作,完成后再释放,那么代码就可以写成下面这样:
1
2
3
4
5
6
7
8
9
10
11some_lock = threading.Lock()
some_lock.acquire()
try:
...
finally:
some_lock.release()
### 而对应的 with 语句,同样非常简洁:
some_lock = threading.Lock()
with somelock:
...上下文管理器的实现: 自定义了一个上下文管理类 FileManager,模拟 Python 的打开、关闭文件操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class FileManager:
def __init__(self, name, mode):
print('calling __init__ method')
self.name = name
self.mode = mode
self.file = None
def __enter__(self):
print('calling __enter__ method')
self.file = open(self.name, self.mode)
return self.file
def __exit__(self, exc_type, exc_val, exc_tb):
print('calling __exit__ method')
if self.file:
self.file.close()
with FileManager('test.txt', 'w') as f:
print('ready to write to file')
f.write('hello world')
## 输出
calling __init__ method
calling __enter__ method
ready to write to file
calling __exit__ method当我们用类来创建上下文管理器时,必须保证这个类包括方法”enter()”和方法“exit()”。其中,方法“enter()”返回需要被管理的资源,方法“exit()”里通常会存在一些释放、清理资源的操作,比如这个例子中的关闭文件等等。
当我们用 with 语句,执行这个上下文管理器时:
1
2with FileManager('test.txt', 'w') as f:
f.write('hello world')下面这四步操作会依次发生:
- 方法“init()”被调用,程序初始化对象 FileManager,使得文件名(name)是”test.txt”,文件模式 (mode) 是’w’;
- 方法“enter()”被调用,文件“test.txt”以写入的模式被打开,并且返回 FileManager 对象赋予变量 f;
- 字符串“hello world”被写入文件“test.txt”;
- 方法“exit()”被调用,负责关闭之前打开的文件流。
值得一提的是,方法“exit()”中的参数“exc_type, exc_val, exc_tb”,分别表示 exception_type、exception_value 和 traceback。当我们执行含有上下文管理器的 with 语句时,如果有异常抛出,异常的信息就会包含在这三个变量中,传入方法“exit()”。
- 数据库的连接操作,也常常用上下文管理器来表示
1
2
3
4
5
6
7
8
9
10
11
12
13
14class DBConnectionManager:
def __init__(self, hostname, port):
self.hostname = hostname
self.port = port
self.connection = None
def __enter__(self):
self.connection = DBClient(self.hostname, self.port)
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.connection.close()
with DBConnectionManager('localhost', '8080') as db_client:
- 方法“init()”负责对数据库进行初始化,也就是将主机名、接口(这里是 localhost 和 8080)分别赋予变量 hostname 和 port;
- 方法“enter()”连接数据库,并且返回对象 DBConnectionManager;
- 方法“exit()”则负责关闭数据库的连接。
基于生成器的上下文管理器
你可以使用装饰器 contextlib.contextmanager,来定义自己所需的基于生成器的上下文管理器,用以支持 with 语句。还是拿前面的类上下文管理器 FileManager 来说,我们也可以用下面形式来表示:1
2
3
4
5
6
7
8
9
10
11
12
13from contextlib import contextmanager
def file_manager(name, mode):
try:
f = open(name, mode)
yield f
finally:
f.close()
with file_manager('test.txt', 'w') as f:
f.write('hello world')这段代码中,函数 file_manager() 是一个生成器,当我们执行 with 语句时,便会打开文件,并返回文件对象 f;当 with 语句执行完后,finally block 中的关闭文件操作便会执行。使用基于生成器的上下文管理器时,我们不再用定义“enter()”和“exit()”方法,但请务必加上装饰器 @contextmanager,这一点新手很容易疏忽。
讲完这两种不同原理的上下文管理器后,还需要强调的是,基于类的上下文管理器和基于生成器的上下文管理器,这两者在功能上是一致的。只不过:
- 于类的上下文管理器更加 flexible,适用于大型的系统开发;
- 而基于生成器的上下文管理器更加方便、简洁,适用于中小型程序。
- 无论你使用哪一种,请不用忘记在方法“exit()”或者是 finally block 中释放资源,这一点尤其重要。
单元测试
说起单元测试,就不得不提 Python unittest 库,它提供了我们需要的大多数工具。我们来看下面这个简单的测试,从代码中了解其使用方法:
1 | import unittest |
首先,我们需要创建一个类TestSort,继承类‘unittest.TestCase’;然后,在这个类中定义相应的测试函数 test_sort(),进行测试。注意,测试函数要以‘test’开头,而测试函数的内部,通常使用 assertEqual()、assertTrue()、assertFalse() 和 assertRaise() 等 assert 语句对结果进行验证。
介绍 Python 单元测试的几个技巧,分别是 mock、side_effect 和 patch。这三者用法不一样,但都是一个核心思想,即用虚假的实现,来替换掉被测试函数的一些依赖项,让我们能把更多的精力放在需要被测试的功能上。
mock 是单元测试中最核心重要的一环。mock 的意思,便是通过一个虚假对象,来代替被测试函数或模块需要的对象。举个例子,比如你要测一个后端 API 逻辑的功能性,但一般后端 API 都依赖于数据库、文件系统、网络等。这样,你就需要通过 mock,来创建一些虚假的数据库层、文件系统层、网络层对象,以便可以简单地对核心后端逻辑单元进行测试。Python mock 则主要使用 mock 或者 MagicMock 对象,这里我也举了一个代码示例。这个例子看上去比较简单,但是里面的思想很重要。下面我们一起来看下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import unittest
from unittest.mock import MagicMock
class A(unittest.TestCase):
def m1(self):
val = self.m2()
self.m3(val)
def m2(self):
pass
def m3(self, val):
pass
def test_m1(self):
a = A()
a.m2 = MagicMock(return_value="custom_val")
a.m3 = MagicMock()
a.m1()
self.assertTrue(a.m2.called) # 验证 m2 被 call 过
a.m3.assert_called_with("custom_val") # 验证 m3 被指定参数 call 过
if __name__ == '__main__':
unittest.main(argv=['first-arg-is-ignored'], exit=False)
## 输出
..
----------------------------------------------------------------------
Ran 2 tests in 0.002s
OK这段代码中,我们定义了一个类的三个方法 m1()、m2()、m3()。我们需要对 m1() 进行单元测试,但是 m1() 取决于 m2() 和 m3()。如果 m2() 和 m3() 的内部比较复杂, 你就不能只是简单地调用 m1() 函数来进行测试,可能需要解决很多依赖项的问题。
Mock Side Effect: 就是 mock 的函数,属性是可以根据不同的输入,返回不同的数值,而不只是一个 return_value。
比如下面这个示例,例子很简单,测试的是输入参数是否为负数,输入小于 0 则输出为 1 ,否则输出为 2。代码很简短,你一定可以看懂,这便是 Mock Side Effect 的用法。1
2
3
4
5
6
7
8
9
10
11
12
13
14from unittest.mock import MagicMock
def side_effect(arg):
if arg < 0:
return 1
else:
return 2
mock = MagicMock()
mock.side_effect = side_effect
mock(-1)
1
mock(1)
2至于 patch,给开发者提供了非常便利的函数 mock 方法。它可以应用 Python 的 decoration 模式或是 context manager 概念,快速自然地 mock 所需的函数。它的用法也不难,我们来看代码:
1
2
3
4
5
6from unittest.mock import patch
def test_sort(self, mock_sort):
...
...在这个 test 里面,mock_sort 替代 sort 函数本身的存在,所以,我们可以像开始提到的 mock object 一样,设置 return_value 和 side_effect。
另一种 patch 的常见用法,是 mock 类的成员函数,这个技巧我们在工作中也经常会用到,比如说一个类的构造函数非常复杂,而测试其中一个成员函数并不依赖所有初始化的 object。它的用法如下1
2with patch.object(A, '__init__', lambda x: None):
…代码应该也比较好懂。在 with 语句里面,我们通过 patch,将 A 类的构造函数 mock 为一个 do nothing 的函数,这样就可以很方便地避免一些复杂的初始化(initialization)。
- Test Coverage: 衡量代码中语句被 cover 的百分比。 https://coverage.readthedocs.io/en/v4.5.x/ 。
- 模块化: 正确的测试方法,应该是先模块化代码这段代码的大概意思是,先有个预处理,再排序,最后再处理一下然后返回。如果现在要求你,给这个函数写个单元测试,你是不是会一筹莫展呢?这个函数确实有点儿复杂,以至于你都不知道应该是怎样的输入,并要期望怎样的输出。这种代码写单元测试是非常痛苦的,更别谈 cover 每条语句的要求了。所以,正确的测试方法,应该是先模块化代码,写成下面的形式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def work(arr):
# pre process
...
...
# sort
l = len(arr)
for i in range(0, l):
for j in range(i + 1, j):
if arr[i] >= arr[j]:
tmp = arr[i]
arr[i] = arr[j]
arr[j] = tmp
# post process
...
...
Return arr接着再进行相应的测试,测试三个子函数的功能正确性;然后通过 mock 子函数,调用 work() 函数,来验证三个子函数被 call 过。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def preprocess(arr):
...
...
return arr
def sort(arr):
...
...
return arr
def postprocess(arr):
...
return arr
def work(self):
arr = preprocess(arr)
arr = sort(arr)
arr = postprocess(arr)
return arr1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19from unittest.mock import patch
def test_preprocess(self):
...
def test_sort(self):
...
def test_postprocess(self):
...
def test_work(self,mock_post_process, mock_sort, mock_preprocess):
work()
self.assertTrue(mock_post_process.called)
self.assertTrue(mock_sort.called)
self.assertTrue(mock_preprocess.called)
pdb & cProfile
在实际生产环境中,对代码进行调试和性能分析,是一个永远都逃不开的话题。调试和性能分析的主要场景,通常有这么三个:
- 一是代码本身有问题,需要我们找到 root cause 并修复;
- 二是代码效率有问题,比如过度浪费资源,增加 latency,因此需要我们 debug;
- 三是在开发新的 feature 时,一般都需要测试。
pdb 的必要性: 在程序中相应的地方打印,的确是调试程序的一个常用手段,但这只适用于小型程序。因为你每次都得重新运行整个程序,或是一个完整的功能模块,才能看到打印出来的变量值。如果程序不大,每次运行都非常快,那么使用 print(),的确是很方便的。
如何使用 pdb: 要启动 pdb 调试,我们只需要在程序中,加入“import pdb”和“pdb.set_trace()”这两行代码就行了,比如下面这个简单的例子:
1
2
3
4
5
6a = 1
b = 2
import pdb
pdb.set_trace()
c = 3
print(a + b + c)当我们运行这个程序时时,它的输出界面是下面这样的,表示程序已经运行到了“pdb.set_trace()”这行,并且暂停了下来,等待用户输入。
1
2> /Users/feiyang/test.py(5)<module>()
-> c = 3这时,我们就可以执行,在 IDE 断点调试器中可以执行的一切操作,比如打印,语法是”p
“: 1
2
3
4(pdb) p a
1
(pdb) p b
2你可以看到,我打印的是 a 和 b 的值,分别为 1 和 2,与预期相符。为什么不打印 c 呢?显然,打印 c 会抛出异常,因为程序目前只运行了前面几行,此时的变量 c 还没有被定义:
1
2(pdb) p c
*** NameError: name 'c' is not defined除了打印,常见的操作还有“n”,表示继续执行代码到下一行,用法如下
1
2(pdb) n
-> print(a + b + c)而命令”l“,则表示列举出当前代码行上下的 11 行源代码,方便开发者熟悉当前断点周围的代码状态:
1
2
3
4
5
6
7(pdb) l
1 a = 1
2 b = 2
3 import pdb
4 pdb.set_trace()
5 -> c = 3
6 print(a + b + c)命令“s“,就是 step into 的意思,即进入相对应的代码内部。这时,命令行中会显示”–Call–“的字样,当你执行完内部的代码块后,命令行中则会出现”–Return–“的字样。我们来看下面这个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43def func():
print('enter func()')
a = 1
b = 2
import pdb
pdb.set_trace()
func()
c = 3
print(a + b + c)
# pdb
> /Users/feiyang/test.py(9)<module>()
-> func()
(pdb) s
--Call--
> /Users/feiyang/test.py(1)func()
-> def func():
(Pdb) l
1 -> def func():
2 print('enter func()')
3
4
5 a = 1
6 b = 2
7 import pdb
8 pdb.set_trace()
9 func()
10 c = 3
11 print(a + b + c)
(Pdb) n
> /Users/feiyang/test.py(2)func()
-> print('enter func()')
(Pdb) n
enter func()
--Return--
> /Users/feiyang/test.py(2)func()->None
-> print('enter func()')
(Pdb) n
> /Users/feiyang/test.py(10)<module>()
-> c = 3这里,我们使用命令”s“进入了函数 func() 的内部,显示”–Call–“;而当我们执行完函数 func() 内部语句并跳出后,显示”–Return–“。
- 与之相对应的命令”r“,表示 step out,即继续执行,直到当前的函数完成返回。
- 命令”b [ ([filename:]lineno | function) [, condition] ]“可以用来设置断点。比方说,我想要在代码中的第 10 行,再加一个断点,那么在 pdb 模式下输入”b 11“即可。
- 而”c“则表示一直执行程序,直到遇到下一个断点。
可以参考对应的官方文档(https://docs.python.org/3/library/pdb.html#module-pdb),来熟悉这些用法。
用 cProfile 进行性能分析: 这里所谓的 profile,是指对代码的每个部分进行动态的分析,比如准确计算出每个模块消耗的时间等。这样你就可以知道程序的瓶颈所在,从而对其进行修正或优化。
比如我想计算斐波拉契数列,运用递归思想,我们很容易就能写出下面这样的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def fib_seq(n):
res = []
if n > 0:
res.extend(fib_seq(n-1))
res.append(fib(n))
return res
fib_seq(30)接下来,我想要测试一下这段代码总的效率以及各个部分的效率。那么,我就只需在开头导入 cProfile 这个模块,并且在最后运行 cProfile.run() 就可以了:
1
2
3
4import cProfile
# def fib(n)
# def fib_seq(n):
cProfile.run('fib_seq(30)')结果如下
1 | /Users/yang.fei/python/my_test/venv/bin/python /Users/yang.fei/python/my_test/test.py |
或者更简单一些,直接在运行脚本的命令中,加入选项“-m cProfile”也很方便: python3 -m cProfile xxx.py
- 参数介绍:
- ncalls,是指相应代码 / 函数被调用的次数;
- tottime,是指对应代码 / 函数总共执行所需要的时间(注意,并不包括它调用的其他代码 / 函数的执行时间);
- tottime percall,就是上述两者相除的结果,也就是tottime / ncalls;
- cumtime,则是指对应代码 / 函数总共执行所需要的时间,这里包括了它调用的其他代码 / 函数的执行时间;
- cumtime percall,则是 cumtime 和 ncalls 相除的平均结果。
了解这些参数后,再来看结果。我们可以清晰地看到,这段程序执行效率的瓶颈,在于第三行的函数 fib(),它被调用了 700 多万次。
- 有没有什么办法可以提高改进呢?答案是肯定的。通过观察,我们发现,程序中有很多对 fib() 的调用,其实是重复的,那我们就可以用字典来保存计算过的结果,防止重复。改进后的代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43def memoize(f):
memo = {}
def helper(x):
if x not in memo:
memo[x] = f(x)
return memo[x]
return helper
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def fib_seq(n):
res = []
if n > 0:
res.extend(fib_seq(n-1))
res.append(fib(n))
return res
fib_seq(30)
########### 这次快多了 ############
/Users/yang.fei/python/my_test/venv/bin/python /Users/yang.fei/python/my_test/test.py
215 function calls (127 primitive calls) in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
31 0.000 0.000 0.000 0.000 test.py:15(fib)
31/1 0.000 0.000 0.000 0.000 test.py:25(fib_seq)
89/31 0.000 0.000 0.000 0.000 test.py:7(helper)
1 0.000 0.000 0.000 0.000 {built-in method builtins.exec}
31 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
30 0.000 0.000 0.000 0.000 {method 'extend' of 'list' objects} - 当然,cProfile 还有很多其他功能,还可以结合 stats 类来使用,你可以阅读相应的 官方文档 来了解
选择异常处理方式
- 问题一:应该使用哪种异常处理方式?
第一种,在代码中对数据进行检测,并直接处理与抛出异常。方法一旦抛出异常,那么程序就会终止;
1
2
3
4
5if [condition1]:
raise Exception1('exception 1')
elif [condition2]:
raise Exception2('exception 2')
...第二种,在异常处理代码中进行处理。如果抛出异常,会被程序捕获(catch),程序还会继续运行。
1
2
3
4try:
...
except Exception as e:
...
问题二:先写出能跑起来的代码,后期再优化可以吗?
很明显,这种认知是错误的。我们从一开始写代码时,就必须对功能和规范这两者双管齐下。问题三:代码中写多少注释才合适?
通常来说,我们会在类的开头、函数的开头或者是某一个功能块的开头加上一段描述性的注释,来说明这段代码的功能,并指明所有的输入和输出。除此之外,我们也要求在一些比较 tricky 的代码上方加上注释,帮助阅读者理解代码的含义。另外,必须提醒一点,如果在写好之后修改了代码,那么代码对应的注释一定也要做出相应的修改,不然很容易造成“文不对题”的现象,给别人也给你自己带来困扰。问题四:项目的 API 文档重要吗?
项目的文档,主要是对相应的系统、产品或是功能模块做一个概述,有助于后人理解。以一个 service 为例,其对应的文档通常会包括下面几部分:
- 系统的概述,包括各个组成部分以及工作流程的介绍;
- 每个组成部分的具体介绍,包括必要性、设计原理等等;
- 系统的 performance,包括 latency 等等参数;
- 主要说明如何对系统的各个部分进行修改,主要给出相应的 code pointer 及对应的测试方案。
实战篇
REST 简介
- REST 的全称是表征层状态转移(REpresentational State Transfer),本意是指一种操作资源方法。不过,你不用纠结于这个绕口的名字。换种方式来说,REST 的实质可以理解为:通过 URL 定位资源,用 GET、POST、PUT、DELETE 等动词来描述操作。而满足 REST 要求的接口,就被称为 RESTful 的接口。
- 总的来说,RESTful 接口通常以 HTTP GET 和 POST 形式出现。但并非所有的 GET、POST 请求接口,都是 RESTful 的接口。
- REST 接口的另一个重要要求:无状态。无状态的意思是,每个 REST 请求都是独立的,不需要服务器在会话(Session)中缓存中间状态来完成这个请求。
- 一个 HTTP 请求完成一次完整操作。
WebSocket
- WebSocket 是一种在单个 TCP/TSL 连接上,进行全双工、双向通信的协议。WebSocket 可以让客户端与服务器之间的数据交换变得更加简单高效,服务端也可以主动向客户端推送数据。在 WebSocket API 中,浏览器和服务器只需要完成一次握手,两者之间就可以直接创建持久性的连接,并进行双向数据传输。
数据结构与算法全景
基础数据结构:数组,堆,栈,队列,链表
- 数组自不必多说,Python 中的基础数组,满足 O(1) 的随机查找,和 O(n) 的随机插入。
- 堆,严格来讲,是一种特殊的二叉树,满足 O(nlogn) 的随机插入和删除,以及 O(1) 时间复杂度拿到最大值或者最小值。堆可以用来实现优先队列,还可以在项目中实现多任务调度,有着非常广泛的应用。
- 栈,是一种先进后出的数据结构,入栈和出栈操作都是 O(1) 时间复杂度。
- 队列,和栈对应,不过功能刚好相反,它是一种先进先出的数据结构,一如其名,先排队者先服务。入队和出队也是 O(1) 的时间复杂度。栈和队列都能用数组来实现,但是对空间的规划需要注意,特别是用数组实现的队列,我们通常用的是循环队列。
- 链表,则是另一种线性表,和数组的不同是,它不支持随机访问,你不能通过下标来获取链表的元素。链表的元素通过指针相连,单链表中元素可以指向后者,双链表则是让相邻的元素互相连接。
进阶数据结构:无向图,有向图,树,DAG 图,字典树,哈希表
无向图,是由顶点和边组成的数据结构,一条边连接两个顶点(如果两个顶点是一个,这条边称为自环)。一如其名,“无向”,所以它的边没有指向性。
有向图,和无向图一样都是“图”这种数据结构,不同的是有向图的边有指向性,方向为一个顶点指向另一个顶点。
树这种数据结构,则可以分为有根树和无根树。前者中,最常见的就是我们的二叉树,从顶点开始一级级向下,每个父结点最多有两个子结点。至于无根树,则是一种特殊的无向图,无环连通的无向图被称为无根树,它有很多特别的性质和优点,在离散数学中应用广泛。
DAG 图,也叫做有向无环图,是一种特殊应用的数据结构,在图的动态规划问题中出现甚多。遍历 DAG 图的方式,也就是我们常说的拓扑排序,是一种图算法。DAG 可以认为是链表的图版本,如果说区块链是链表,那么区块链 3.0 时代可能就是 DAG 图。
字典树,又被称为 Trie 树,是一种边为字符的有向图,它在字符串处理中有着非常强大的应用。广为人知的 AC 自动机,就是用 Trie 树来解决多模式字符串匹配问题。Trie 树在工业界也常被拿来做搜索提示,例如你在百度中搜索 “极客时”,就会自动跳出 “极客时间”。
哈希表,这一定是程序员应用最广、自觉最简单的一个数据结构,比如 Python 的 dict() 就可以拿来即用,简单而自然。不过,哈希表其实有着非常深刻的内涵,冲突算法、哈希算法、扩容算法,都很值得我们去深究一下。
算法:二分搜索
算法:深度优先搜索(DFS)和广度优先搜索(BFS)
算法:贪心和动态规划