问题介绍 假设有小费和小王俩好基友,天天形影不离,二人分在一个组。
迟到一次,则当事人记一分。(迟到)
小组两人在某一天同时迟到,则小组总分再记一分。(连坐)
一周内如果每天都迟到,则当事人再扣一分。(太皮了)
三种情况可累加记分,一周结算一次小组总分。
举个例子好了 下图为某一周的出勤情况:从图中看出小费同学比较皮,天天迟到!小王同学有两天和小费同学一起开黑,导致了迟到。
那么问题来了:如果已知某一周小组的总分情况,列出可能的出勤表
咸鱼采用的暴力破解法 有两个对象,每个对象有5个记录。每次记录的值有两种情况,我们可以暴力枚举出所有的情况。
所有上面的出勤图就可以简化为0-1数值图:
接下来问题就变成,如何枚举出这1024种情况?
2行5列一共10个值,循环列出0-1111111111二进制数的情况,高位补0。
如上图,2列是独立的,我们只需求出5位的情况,两列互相遍历即可。
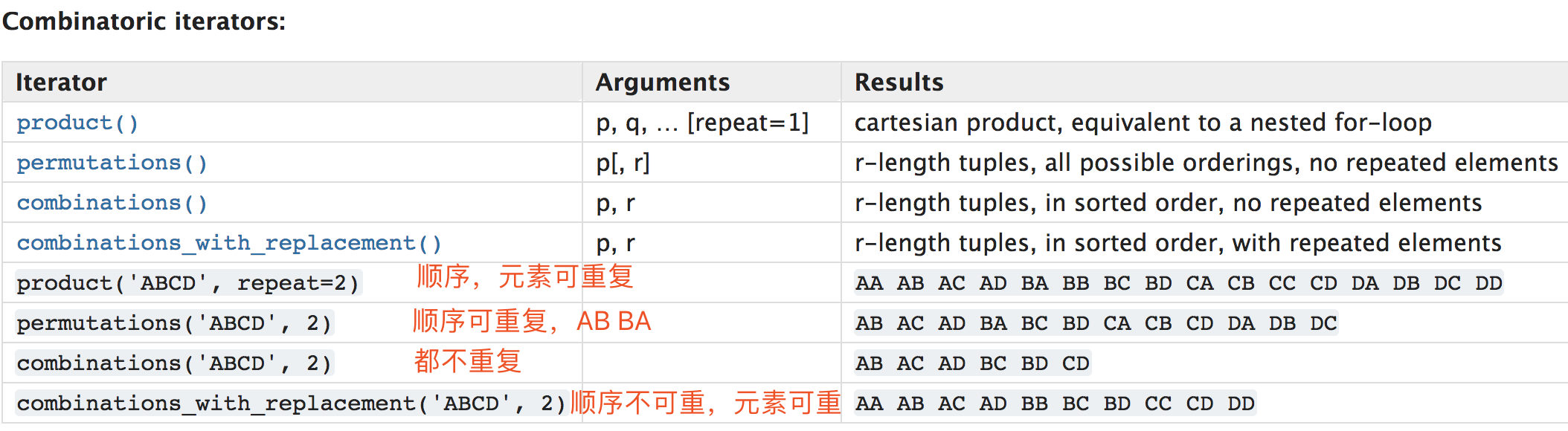
用python自带的 itertools 库,分分钟枚举完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 import itertoolsdef main (start_day,faith_score ): Calendar=[[6 ,6 ,6 ,6 ,6 ],[6 ,6 ,6 ,6 ,6 ]] L=list (itertools.product([0 ,1 ],repeat=5 )) leng=len (L) for i in range (leng): for j in range (leng): Calendar[0 ]=L[i] Calendar[1 ]=L[j] if sumcredit(Calendar)==faith_score: gg=todate(Calendar,start_day) print (gg)
只要有了枚举的所有情况,判断计分则是很容易的事情。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def credit1 (L ): credit=0 for i in L[0 ]: if i==1 : credit+=1 for j in L[1 ]: if j==1 : credit+=1 return credit def credit2 (L): credit=0 for i in range (5 ): if L[0 ][i]==1 and L[1 ][i]==1 : credit+=1 return credit def credit3 (L): credit=0 if 0 not in L[0 ]: credit+=1 if 0 not in L[1 ]: credit+=1 return credit def sumcredit (L ): c1=credit1(L) c2=credit2(L) c3=credit3(L) return c1+c2+c3
时间问题,不容小觑 因为时间在跨月份是时候有点麻烦,不能用普通的++,但我们可以用datetime库呀。timedelta()函数你值得拥有。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from datetime import datetime,timedeltadef get_date (date ): date_begin=datetime.strptime(date,'%Y%m%d' ) time=str (datetime.date(date_begin)) date1=date_begin+timedelta(days=1 ) time1=str (datetime.date(date1)) date2=date_begin+timedelta(days=2 ) time2=str (datetime.date(date2)) date3=date_begin+timedelta(days=2 ) time3=str (datetime.date(date3)) date4=date_begin+timedelta(days=2 ) time4=str (datetime.date(date4)) return time,time1,time2,time3,time4
最后我们在输出 出勤情况的时候,将那个简化后的二维数组List=>日历对应起来。
1 2 3 4 5 6 7 8 9 10 11 def todate (L,date ): time,time1,time2,time3,time4=get_date(date) record=[time+'-小费' ,time+'-小王' ,time1+'-小费' ,time1+'-小王' ,time2+'-小费' ,\ time2+'-小王' ,time3+'-小费' ,time3+'-小王' ,time4+'-小费' ,time4+'-小王' ] L1=L[0 ]+L[1 ] for i in range (len (L1)): if L1[i]==1 : record[i]+='(迟到)' else : record[i]+='(正常)' return record
假设我们输入date=20180305,score=0
1 2 3 4 5 6 ['2018-03-04-小费(正常)' , '2018-03-04-小王(正常)' , '2018-03-05-小费(正常)' , '2018-03-05-小王(正常)' , '2018-03-06-小费(正常)' , '2018-03-06-小王(正常)' , '2018-03-06-小费(正常)' , '2018-03-06-小王(正常)' , '2018-03-06-小费(正常)' , '2018-03-06-小王(正常)' ] [Finished in 0.2 s]
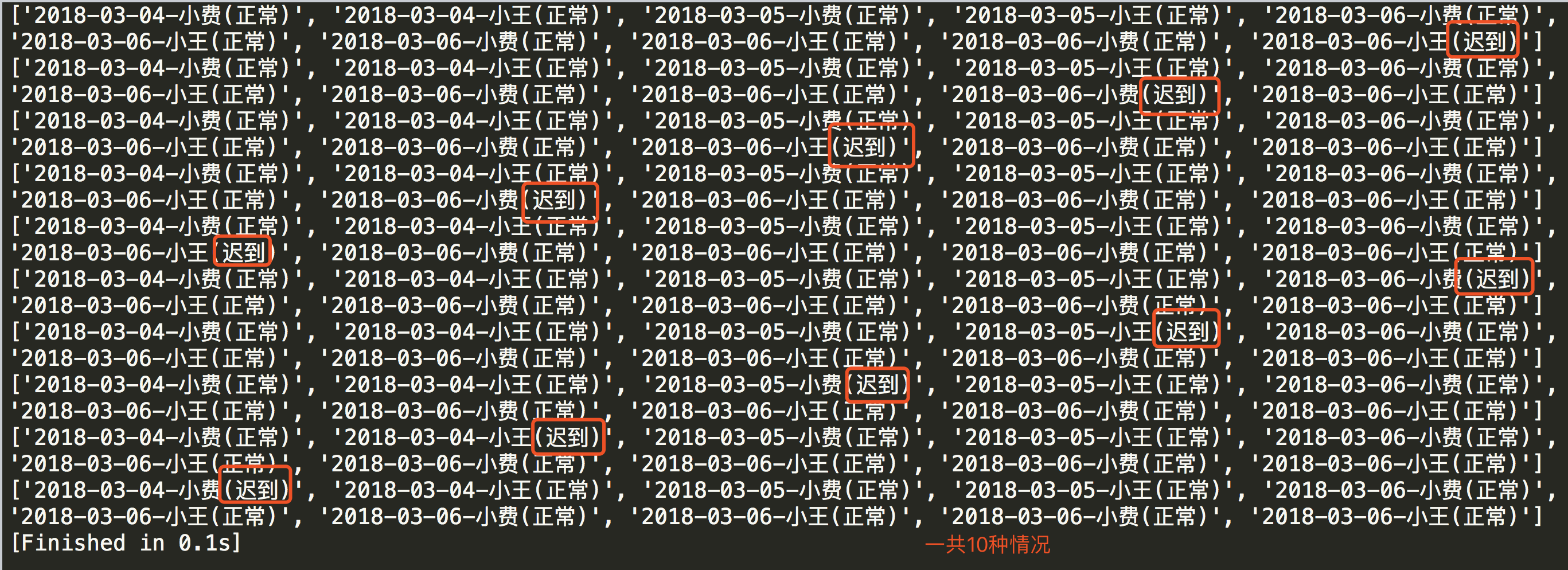
假设我们输入date=20180305,score=1
最后一点废话 有一篇关于itertools的文章这段代码很Pythonic | 相见恨晚的 itertools 库 安利一下。此文章的python源代码
马上就要毕业了,再也没有当学生那种无忧无虑的感觉了。以前贪玩欠的债,找工作的时候哭出来。naive,未来珍惜时间,好好学习。狗住,加油!